


Optix光线追踪渲染器(二)单次射线求交的三维场景渲染
- 26 3 月, 2023
- by
- pladmin
引言
上一节我们搭建了optix基础架构,但是使用的是一个无模型、无射线,更无光照着色的场景。本节我们来逐步引入模型和射线求交的内容。但是注意:本节实现的光追只弹射一次射线,将该射线第一次求交得到的颜色直接作为像素值,并非路径追踪的算法。
Part1. 使用GLFW窗口
本节我们来复现一下example03。
之前我们渲染出来图片以后,使用stb_image_write将图片直接输出到本地。为了更方便地预览渲染结果,甚至日后实现编辑场景功能,我们必须将渲染结果搬到窗口上显示。
我们需要在main.cpp中引用glfWindow/GLFWindow.h 和GL/gl.h这两个头文件,首先将glfwindow文件夹复制到工程,接下来我们右键项目-属性-VC++目录-包含目录,添加一条xxx\3rdParty\glfw\include;在库目录添加glfwindow.lib和glfw3.lib的所在路径;然后在链接-输入里添加glfwindow.lib和glfw3.lib。(如果找不到glfwindow.lib和glfw3.lib,就去编译一下官方的源码或者在网上下一个。这部分就是opengl配置环境那一套了不想多言,出错就百度吧)
接下来我们来定义一下glfw窗口:
struct SampleWindow : public GLFWindow
{
SampleWindow(const std::string& title)
: GLFWindow(title)
{}
virtual void render() override
{
sample.render();
}
virtual void draw() override
{
sample.downloadPixels(pixels.data());
if (fbTexture == 0)
glGenTextures(1, &fbTexture);
glBindTexture(GL_TEXTURE_2D, fbTexture);
GLenum texFormat = GL_RGBA;
GLenum texelType = GL_UNSIGNED_BYTE;
glTexImage2D(GL_TEXTURE_2D, 0, texFormat, fbSize.x, fbSize.y, 0, GL_RGBA,
texelType, pixels.data());
glDisable(GL_LIGHTING);
glColor3f(1, 1, 1);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glEnable(GL_TEXTURE_2D);
glBindTexture(GL_TEXTURE_2D, fbTexture);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glDisable(GL_DEPTH_TEST);
glViewport(0, 0, fbSize.x, fbSize.y);
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
glOrtho(0.f, (float)fbSize.x, 0.f, (float)fbSize.y, -1.f, 1.f);
glBegin(GL_QUADS);
{
glTexCoord2f(0.f, 0.f);
glVertex3f(0.f, 0.f, 0.f);
glTexCoord2f(0.f, 1.f);
glVertex3f(0.f, (float)fbSize.y, 0.f);
glTexCoord2f(1.f, 1.f);
glVertex3f((float)fbSize.x, (float)fbSize.y, 0.f);
glTexCoord2f(1.f, 0.f);
glVertex3f((float)fbSize.x, 0.f, 0.f);
}
glEnd();
}
virtual void resize(const vec2i& newSize)
{
fbSize = newSize;
sample.resize(newSize);
pixels.resize(newSize.x * newSize.y);
}
vec2i fbSize;
GLuint fbTexture{ 0 };
SampleRenderer sample;
std::vector<uint32_t> pixels;
};
这一部分就是opengl的基础了,即使你对它的语法和api不熟,光看函数名和变量名也能猜出来这是干嘛的。首先窗体是一个继承了GlfWindow的类,他的成员包括我们的渲染器SampleRenderer、从设备下载下来的像素pixels、尺寸fbSize以及要绑定在窗口上的2D纹理fbTexture。
一般我们使用一个标题字符串来构造窗口,然后我们可以分别override它的render()、draw()、resize()方法。
glfw的render()方法就是一个渲染回调,因为OpenGL窗口定期要渲染一次画面,本质就是定期调用一次render()方法。在override时,我们就让该窗口定期调用一次SampleRenderer的渲染函数。
glfw的draw()方法就是一个绘制回调,在窗口上绘制像素。这里区分一下渲染和绘制:渲染是后台进行的,绘制是在窗口前台进行的。render未完成的时候也可以中途把render的当前结果拿来draw,这样就能看到绘制过程了。在override时,我们首先通过download函数从管线拿到目前渲染的结果,然后在glfw窗口中定义视口、绑定2D纹理、定位2D纹理,这样就能在窗口中观看到2D纹理上显示的场景渲染结果了。
glfw的resize()顾名思义,当窗口改变大小时,我们要让渲染器的缓冲区尺寸也跟着改变大小。
extern "C" int main(int ac, char** av)
{
try {
SampleWindow* window = new SampleWindow("Optix 7 Course Example");
window->run();
}
catch (std::runtime_error& e) {
std::cout << GDT_TERMINAL_RED << "FATAL ERROR: " << e.what()
<< GDT_TERMINAL_DEFAULT << std::endl;
exit(1);
}
return 0;
}
稍微改动一下main函数,这回我们直接实例化一个SampleWindow,让他运行即可,效果如下:
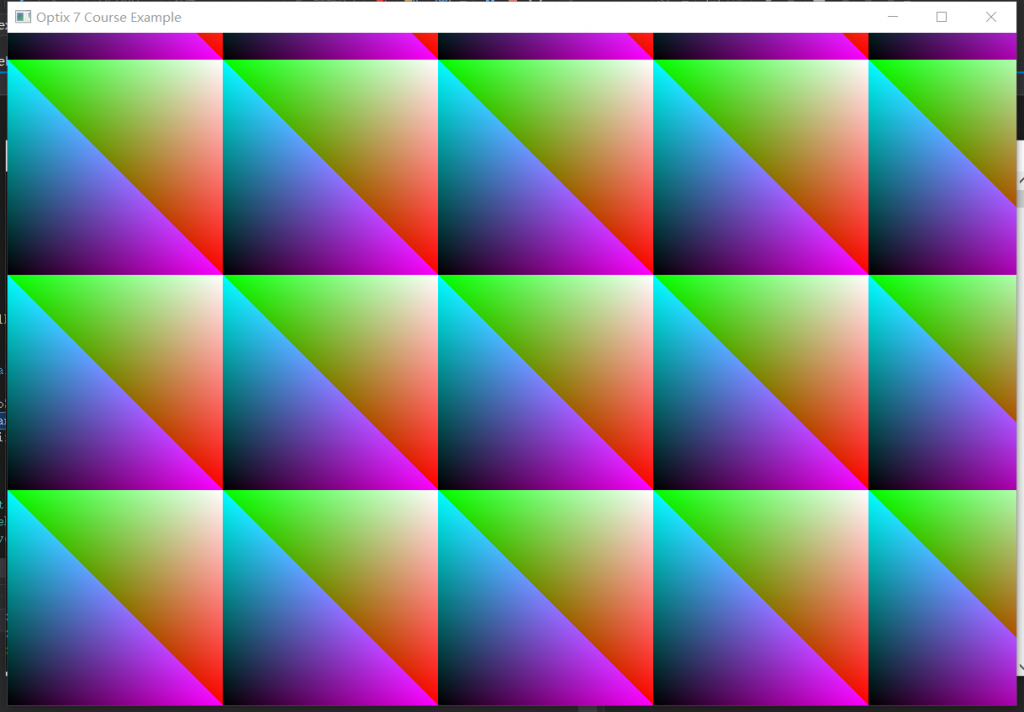
Part.2 三维空间三角形渲染
截至目前,渲染都是2D的。现在我们希望复现example04,将渲染升至三维空间,首先就要考虑要引入哪些新元素:①相机;②三角形;③方体(毕竟单个三角形依然是平面的,多个三角形组成方体就显得立体了);④场景结构(将场景中所有三角面打包构成可加速的求交结构);⑤raygen、miss、hit shader的真正定义(之前几乎全是空的)。
1、缓冲区内容补充
我们定义的LaunchParams缓冲区本质是为gpu端的shader代码服务的,根据前面各种shader的定义可以知道,Raygen shader需要拿到相机位置才能计算第一根发射的光线;hit shader需要拿到场景中的几何结构才能完成求交。因此,我们需要向LaunchParams中补充相机和场景几何结构:
namespace osc {
using namespace gdt;
struct LaunchParams
{
struct {
uint32_t *colorBuffer;
vec2i size;
} frame;
struct {
vec3f position;
vec3f direction;
vec3f horizontal;
vec3f vertical;
} camera;
OptixTraversableHandle traversable;
};
}
camera中定义了position(相机位置)、direction(相机面向的方向)、horizontal(描述相机视口水平的方向和长度)、vertical(描述相机视口竖直的方向和长度)。之所以需要horizontal和vertical这两个参量是因为它们能告诉Raygen shader 视口一共要发射多少像素、从哪里发射。
而traversable就是我们的场景几何结构了,类型是optix定义的OptixTraversableHandle类型,这是一个经过特殊处理(为了求交加速)的包含了场景所有三角形或其他形状的数据结构。后面会讲这个东西怎么用。
2、相机
在窗口中,我们鼠标操控的是glfwindows的内置相机,这个内置相机是包括position、direction、up三个方位向量的经典相机,并且还有一些其他的冗余信息。如果我们直接把glfwindows的相机传送给LaunchParams,会显得非常臃肿。所以我们再在SampleRenderer.h定义一个额外的相机Camera,参量也是position、direction、up,让他去把glfwindows内置相机的参数下载下来,再调用咱们自写的setCamera()函数,把参数换算给LaunchParams的camera。
SampleRenderer.h:
struct Camera {
vec3f from;
vec3f at;
vec3f up;
};
class SampleRenderer{
...
void setCamera(const Camera& camera);
...
Camera lastSetCamera;
}
setCamera就是根据当前的glfwindows内置相机,或我们新定义的相机,计算出position、direction、horizontal、vertical的值并更新到LaunchParams的camera中。这里额外定义了一个lastSetCamera变量,这个是当窗口触发resize的时候,需要临时更新LaunchParams的camera,这时省的再去glfw里拿新相机了,直接使用上一次setCamera时存的值即可。
SampleRenderer.cpp:
void SampleRenderer::render()
{
// sanity check: make sure we launch only after first resize is
// already done:
if (launchParams.frame.size.x == 0) return;
launchParamsBuffer.upload(&launchParams, 1);
OPTIX_CHECK(optixLaunch(/*! pipeline we're launching launch: */
pipeline, stream,
/*! parameters and SBT */
launchParamsBuffer.d_pointer(),
launchParamsBuffer.sizeInBytes,
&sbt,
/*! dimensions of the launch: */
launchParams.frame.size.x,
launchParams.frame.size.y,
1
));
// sync - make sure the frame is rendered before we download and
// display (obviously, for a high-performance application you
// want to use streams and double-buffering, but for this simple
// example, this will have to do)
CUDA_SYNC_CHECK();
}
void SampleRenderer::setCamera(const Camera &camera)
{
lastSetCamera = camera;
launchParams.camera.position = camera.from;
launchParams.camera.direction = normalize(camera.at-camera.from);
const float cosFovy = 0.66f;
const float aspect = launchParams.frame.size.x / float(launchParams.frame.size.y);
launchParams.camera.horizontal
= cosFovy * aspect * normalize(cross(launchParams.camera.direction,
camera.up));
launchParams.camera.vertical
= cosFovy * normalize(cross(launchParams.camera.horizontal,
launchParams.camera.direction));
}
void SampleRenderer::resize(const vec2i &newSize)
{
// if window minimized
if (newSize.x == 0 | newSize.y == 0) return;
// resize our cuda frame buffer
colorBuffer.resize(newSize.x*newSize.y*sizeof(uint32_t));
// update the launch parameters that we'll pass to the optix
// launch:
launchParams.frame.size = newSize;
launchParams.frame.colorBuffer = (uint32_t*)colorBuffer.d_pointer();
// and re-set the camera, since aspect may have changed
setCamera(lastSetCamera);
}
render()函数里主要纠正一些变量名;新增的setCamera()代码还是比较通俗的。cosFovy是视口的纵向张角的cosine值,cosFovy越大-视野越广。注意每次调用setCamera后预存一下lastSetCamera,这样当窗口发生resize的时候,resize函数直接用lastSetCamera来调用setCamera就很方便了。
main.cpp:
struct SampleWindow : public GLFWindow
{
SampleWindow(const std::string& title)
: GLFWindow(title)
{}
virtual void render() override
{
if (cameraFrame.modified) {
sample.setCamera(Camera{ cameraFrame.get_from(),
cameraFrame.get_at(),
cameraFrame.get_up() });
cameraFrame.modified = false;
}
sample.render();
}
3、三角模型
无论是C++光栅化渲染器还是C++光线追踪渲染器,我都已经定义过多次三角模型了,所以这里我不想太多费口舌了。。。
首先我们在SampleRenderer.h中定义一个TriangleMesh类,用来保存一个或多个模型的所有顶点、三角面(后续还会有法线)信息。
SampleRenderer.h:
#include "gdt/math/AffineSpace.h"
struct TriangleMesh {
/*! add a unit cube (subject to given xfm matrix) to the current
triangleMesh */
void addUnitCube(const affine3f &xfm);
//! add aligned cube aith front-lower-left corner and size
void addCube(const vec3f ¢er, const vec3f &size);
std::vector<vec3f> vertex;
std::vector<vec3i> index;
};
如上代码所示,vertex就保存模型的所有顶点,index就保存模型三角面的索引(比如0,1,2,1,2,3的索引代表012构成第一个三角形,123构成第二个三角形)。为了方便构造立方体实例,定义了个addCube和addUnitCube函数。addCube就是给定立方体的位置和尺寸,得到立方体的三个轴的方向和长度,然后调用addUnitCube;addUnitCube就是根据轴来计算每个顶点的位置,然后构成索引面,将顶点和面放到该TriangleMesh的vertex和index组里。
SampleRenderer.cpp:
void TriangleMesh::addCube(const vec3f& center, const vec3f& size)
{
affine3f xfm;
xfm.p = center - 0.5f * size;
xfm.l.vx = vec3f(size.x, 0.f, 0.f);
xfm.l.vy = vec3f(0.f, size.y, 0.f);
xfm.l.vz = vec3f(0.f, 0.f, size.z);
addUnitCube(xfm);
}
/*! add a unit cube (subject to given xfm matrix) to the current
triangleMesh */
void TriangleMesh::addUnitCube(const affine3f& xfm)
{
int firstVertexID = (int)vertex.size();
vertex.push_back(xfmPoint(xfm, vec3f(0.f, 0.f, 0.f)));
vertex.push_back(xfmPoint(xfm, vec3f(1.f, 0.f, 0.f)));
vertex.push_back(xfmPoint(xfm, vec3f(0.f, 1.f, 0.f)));
vertex.push_back(xfmPoint(xfm, vec3f(1.f, 1.f, 0.f)));
vertex.push_back(xfmPoint(xfm, vec3f(0.f, 0.f, 1.f)));
vertex.push_back(xfmPoint(xfm, vec3f(1.f, 0.f, 1.f)));
vertex.push_back(xfmPoint(xfm, vec3f(0.f, 1.f, 1.f)));
vertex.push_back(xfmPoint(xfm, vec3f(1.f, 1.f, 1.f)));
int indices[] = { 0,1,3, 2,3,0,
5,7,6, 5,6,4,
0,4,5, 0,5,1,
2,3,7, 2,7,6,
1,5,7, 1,7,3,
4,0,2, 4,2,6
};
for (int i = 0; i < 12; i++)
index.push_back(firstVertexID + vec3i(indices[3 * i + 0],
indices[3 * i + 1],
indices[3 * i + 2]));
}
xfm是用来定义立方体的轴心和三维轴的。得到轴以后,调用的addUnitCube()就可以根据轴心和三维轴算出立方体每个顶点的位置(这种设计模式有点晦涩,大家可以根据自己喜好重写一下这些逻辑)。
要注意的是,一个TriangleMesh未必只有一个立方体,因此在添加新立方体的时候,先要获取前面已经有多少vertex了,此时你新立方体真正的顶点索引=前面立方体vertex的总数+当前立方体内该顶点的索引。
4、场景加速结构构造
首先我们在SampleRenderer.h中继续补充一个函数和几个参量:
SampleRenderer.h:
class SampleRenderer
{
...
OptixTraversableHandle buildAccel(const TriangleMesh &model);
...
const TriangleMesh model;
CUDABuffer vertexBuffer;
CUDABuffer indexBuffer;
//! buffer that keeps the (final, compacted) accel structure
CUDABuffer asBuffer;
}
首先实例化一个模型实例model,然后申请三个gpu端的buffer,用来分别临时存储顶点数据、索引数据和加速结构数据。后面解释这几个buffer怎么用。
SampleRenderer.cpp:
OptixTraversableHandle SampleRenderer::buildAccel(const TriangleMesh &model)
{
// upload the model to the device: the builder
vertexBuffer.alloc_and_upload(model.vertex);
indexBuffer.alloc_and_upload(model.index);
OptixTraversableHandle asHandle { 0 };
// ==================================================================
// triangle inputs
// ==================================================================
OptixBuildInput triangleInput = {};
triangleInput.type
= OPTIX_BUILD_INPUT_TYPE_TRIANGLES;
// create local variables, because we need a *pointer* to the
// device pointers
CUdeviceptr d_vertices = vertexBuffer.d_pointer();
CUdeviceptr d_indices = indexBuffer.d_pointer();
triangleInput.triangleArray.vertexFormat = OPTIX_VERTEX_FORMAT_FLOAT3;
triangleInput.triangleArray.vertexStrideInBytes = sizeof(vec3f);
triangleInput.triangleArray.numVertices = (int)model.vertex.size();
triangleInput.triangleArray.vertexBuffers = &d_vertices;
triangleInput.triangleArray.indexFormat = OPTIX_INDICES_FORMAT_UNSIGNED_INT3;
triangleInput.triangleArray.indexStrideInBytes = sizeof(vec3i);
triangleInput.triangleArray.numIndexTriplets = (int)model.index.size();
triangleInput.triangleArray.indexBuffer = d_indices;
uint32_t triangleInputFlags[1] = { 0 };
// in this example we have one SBT entry, and no per-primitive
// materials:
triangleInput.triangleArray.flags = triangleInputFlags;
triangleInput.triangleArray.numSbtRecords = 1;
triangleInput.triangleArray.sbtIndexOffsetBuffer = 0;
triangleInput.triangleArray.sbtIndexOffsetSizeInBytes = 0;
triangleInput.triangleArray.sbtIndexOffsetStrideInBytes = 0;
// ==================================================================
// BLAS setup
// ==================================================================
OptixAccelBuildOptions accelOptions = {};
accelOptions.buildFlags = OPTIX_BUILD_FLAG_NONE
| OPTIX_BUILD_FLAG_ALLOW_COMPACTION
;
accelOptions.motionOptions.numKeys = 1;
accelOptions.operation = OPTIX_BUILD_OPERATION_BUILD;
OptixAccelBufferSizes blasBufferSizes;
OPTIX_CHECK(optixAccelComputeMemoryUsage
(optixContext,
&accelOptions,
&triangleInput,
1, // num_build_inputs
&blasBufferSizes
));
// ==================================================================
// prepare compaction
// ==================================================================
CUDABuffer compactedSizeBuffer;
compactedSizeBuffer.alloc(sizeof(uint64_t));
OptixAccelEmitDesc emitDesc;
emitDesc.type = OPTIX_PROPERTY_TYPE_COMPACTED_SIZE;
emitDesc.result = compactedSizeBuffer.d_pointer();
// ==================================================================
// execute build (main stage)
// ==================================================================
CUDABuffer tempBuffer;
tempBuffer.alloc(blasBufferSizes.tempSizeInBytes);
CUDABuffer outputBuffer;
outputBuffer.alloc(blasBufferSizes.outputSizeInBytes);
OPTIX_CHECK(optixAccelBuild(optixContext,
/* stream */0,
&accelOptions,
&triangleInput,
1,
tempBuffer.d_pointer(),
tempBuffer.sizeInBytes,
outputBuffer.d_pointer(),
outputBuffer.sizeInBytes,
&asHandle,
&emitDesc,1
));
CUDA_SYNC_CHECK();
// ==================================================================
// perform compaction
// ==================================================================
uint64_t compactedSize;
compactedSizeBuffer.download(&compactedSize,1);
asBuffer.alloc(compactedSize);
OPTIX_CHECK(optixAccelCompact(optixContext,
/*stream:*/0,
asHandle,
asBuffer.d_pointer(),
asBuffer.sizeInBytes,
&asHandle));
CUDA_SYNC_CHECK();
// ==================================================================
// aaaaaand .... clean up
// ==================================================================
outputBuffer.free(); // << the UNcompacted, temporary output buffer
tempBuffer.free();
compactedSizeBuffer.free();
return asHandle;
}
上面这段代码就是本文的精华部分了。但说句实话,基本又全是套路式地调用api…所以我也是一知半解。尝试解读一下这段代码,首先我们要将模型的顶点和索引上传到vertex和index两个buffer中,然后定义一个triangleInput,将这两大缓冲区送入注册绑定;同时每个物体要通过sbt对shader进行绑定,不过这个example没有特殊材质shader,所有的三角面最后都绑定一个相同的hit group shader。
上述信息都绑定好后,便开始配置加速结构、创建加速结构、申请加速结构的缓冲空间,然后执行加速结构(optixAccelBuild),再进行一步压缩,最终得到了OptixTraversableHandle类型的完整加速结构,存在asHandle中。
在渲染器初始化的时候,我们需要在着色器实例已完成、管线搭建之前构造好这个加速结构,并将它配置进LaunchParams中。
SampleRenderer.cpp:
SampleRenderer::SampleRenderer()
{
...
createHitgroupPrograms();
launchParams.traversable = buildAccel(model);
std::cout << "#osc: setting up optix pipeline ..." << std::endl;
createPipeline();
...
}
5、着色器
虽然说本节的精华部分在加速结构的构造上,但实际上最有含金量的内容仍然是我们的shader部分。在前面几个example中shader基本都是空白,没有任何光追相关的行为,这一节我们就要写入正儿八经的光追shader。
首先我们补充几个基础函数:
devicePrograms.cu:
enum { SURFACE_RAY_TYPE=0, RAY_TYPE_COUNT };
static __forceinline__ __device__
void *unpackPointer( uint32_t i0, uint32_t i1 )
{
const uint64_t uptr = static_cast<uint64_t>( i0 ) << 32 | i1;
void* ptr = reinterpret_cast<void*>( uptr );
return ptr;
}
static __forceinline__ __device__
void packPointer( void* ptr, uint32_t& i0, uint32_t& i1 )
{
const uint64_t uptr = reinterpret_cast<uint64_t>( ptr );
i0 = uptr >> 32;
i1 = uptr & 0x00000000ffffffff;
}
template<typename T>
static __forceinline__ __device__ T *getPRD()
{
const uint32_t u0 = optixGetPayload_0();
const uint32_t u1 = optixGetPayload_1();
return reinterpret_cast<T*>( unpackPointer( u0, u1 ) );
}
SURFACE_RAY_TYPE就是选择射线类型,射线类型不仅包括传统的计算光色的射线,还有计算阴影的射线。这里我们只使用传统默认的光色射线。
unpackPainter和packPainter就是对某个指针中保存的地址进行高32位和低32位的拆分和合并。之所以需要拆分,是因为我们的计算机是64位的所以指针也是64位的,然而gpu的寄存器是32位的,因此只能将指针拆分成两部分存进gpu的寄存器。
这里简单解释下payload,payload就类似一个负载寄存器,负责在不同shader之间传递信息。后面我们会在Raygen Shader中申请一个颜色指针来存储最终的光追颜色,当开始tracing后,会将这个颜色指针拆分(pack)写入0号和1号寄存器,当Hit Shader和Miss Shader想往里面写东西时,就可以通过上面代码中的getPRD函数获得0号和1号寄存器中的值,将其unpack便得到了那个颜色指针,然后就可以往这个颜色指针里写内容了。
接下来我们分别编写一下Hit、Miss、RayGen shader。首先是Hit Shader:
extern "C" __global__ void __closesthit__radiance()
{
const int primID = optixGetPrimitiveIndex();
vec3f &prd = *(vec3f*)getPRD<vec3f>();
prd = gdt::randomColor(primID);
}
extern "C" __global__ void __anyhit__radiance()
{ /*! for this simple example, this will remain empty */ }
因为场景没有半透明的物体,因此AnyHit暂时不需要写东西。ClosetHit必然要写了(因为它相当于BSDF函数),这一节我们不需要任何复杂光照模型,直接根据三角面索引给一个随机颜色就好了:首先通过optixGetPrimitiveIndex获得当前击中的三角面索引并以此生成一个随机颜色,然后获得把颜色放进0号、1号寄存器,这样就完成了着色过程。
接下来是Miss Shader:
extern "C" __global__ void __miss__radiance()
{
vec3f &prd = *(vec3f*)getPRD<vec3f>();
// set to constant white as background color
prd = vec3f(1.f);
}
这个更简单,直接返回纯色(1,1,1)。
最后是最复杂的Raygen Shader:
extern "C" __global__ void __raygen__renderFrame()
{
// compute a test pattern based on pixel ID
const int ix = optixGetLaunchIndex().x;
const int iy = optixGetLaunchIndex().y;
const auto &camera = optixLaunchParams.camera;
// our per-ray data for this example. what we initialize it to
// won't matter, since this value will be overwritten by either
// the miss or hit program, anyway
vec3f pixelColorPRD = vec3f(0.f);
// the values we store the PRD pointer in:
uint32_t u0, u1;
packPointer( &pixelColorPRD, u0, u1 );
// normalized screen plane position, in [0,1]^2
const vec2f screen(vec2f(ix+.5f,iy+.5f)
/ vec2f(optixLaunchParams.frame.size));
// generate ray direction
vec3f rayDir = normalize(camera.direction
+ (screen.x - 0.5f) * camera.horizontal
+ (screen.y - 0.5f) * camera.vertical);
optixTrace(optixLaunchParams.traversable,
camera.position,
rayDir,
0.f, // tmin
1e20f, // tmax
0.0f, // rayTime
OptixVisibilityMask( 255 ),
OPTIX_RAY_FLAG_DISABLE_ANYHIT,//OPTIX_RAY_FLAG_NONE,
SURFACE_RAY_TYPE, // SBT offset
RAY_TYPE_COUNT, // SBT stride
SURFACE_RAY_TYPE, // missSBTIndex
u0, u1 );
const int r = int(255.99f*pixelColorPRD.x);
const int g = int(255.99f*pixelColorPRD.y);
const int b = int(255.99f*pixelColorPRD.z);
// convert to 32-bit rgba value (we explicitly set alpha to 0xff
// to make stb_image_write happy ...
const uint32_t rgba = 0xff000000
| (r<<0) | (g<<8) | (b<<16);
// and write to frame buffer ...
const uint32_t fbIndex = ix+iy*optixLaunchParams.frame.size.x;
optixLaunchParams.frame.colorBuffer[fbIndex] = rgba;
}
因为我们现在已经有了相机、有了视口,所以当我们枚举每一个像素的时候,我们可以算出这个像素从哪里、向什么方向发射第一根射线。首先通过vec2f(ix+.5f,iy+.5f) / vec2f(optixLaunchParams.frame.size)算出当前像素的x、y坐标位于视口的多少百分比的位置,然后根据这个百分比算出这个像素发射的光线向什么方向偏。
这里定义了一个pixelColorPRD来存储该像素的最终颜色,通过packPointer将其分为u0、u1两部分,在调用optixTrace这个开始渲染的终极函数时,u0和u1就会自动被写入gpu的0号和1号寄存器中,方便hit和miss shader往里面写入颜色结果。
关于optixTrace函数其实没啥想说的,optix最精华的封装就在这里了,把相机、场景、射线属性、寄存信息(u0和u1)传值进去就ok了,天花乱坠的求交便在这里发生。等光追结束了,把我们存的颜色指针pixelColorPRD中的rgb值算出来,写入LaunchParams的frame中即可。
当然还是老样子,写完.cu立刻编译cuda,编译完得到ptx机器码后用python将其parse成MyShader.c文件放到目录下,这样SampleRenderer.cpp中的embedded_ptx_code[]就能获取到机器码。(当然因为我们main.cpp的代码还没改,所以此时编译以后出现runtime error是正常的,不要紧张。当务之急就是拿到ptx机器码)
6、渲染
回到main.cpp函数,定义一下我们的场景。
main.cpp:
struct SampleWindow : public GLFCameraWindow
{
SampleWindow(const std::string& title,
const TriangleMesh& model,
const Camera& camera,
const float worldScale)
: GLFCameraWindow(title, camera.from, camera.at, camera.up, worldScale),
sample(model)
{
}
virtual void render() override
{
if (cameraFrame.modified) {
sample.setCamera(Camera{ cameraFrame.get_from(),
cameraFrame.get_at(),
cameraFrame.get_up() });
cameraFrame.modified = false;
}
sample.render();
}
首先glfw继承的窗口要改成GLFCameraWindow,因为这个类带有相机,并且可以直接用鼠标操纵相机,非常方便。构造函数需要稍作修改,需要提前把场景中的模型、相机、世界尺度这些信息传入,给GLFwindow自带的camera传入一个初始值。
接下来改写一下render函数,当鼠标交互场景导致GLFwindow的相机发生变化时,就会触发SampleRenderer的setCamera函数,同步更新到LaunchParams的camera中。
extern "C" int main(int ac, char** av)
{
try {
TriangleMesh model;
// 100x100 thin ground plane
model.addCube(vec3f(0.f, -1.5f, 0.f), vec3f(10.f, .1f, 10.f));
// a unit cube centered on top of that
model.addCube(vec3f(0.f, 0.f, 0.f), vec3f(2.f, 2.f, 2.f));
Camera camera = { /*from*/vec3f(-10.f,2.f,-12.f),
/* at */vec3f(0.f,0.f,0.f),
/* up */vec3f(0.f,1.f,0.f) };
// something approximating the scale of the world, so the
// camera knows how much to move for any given user interaction:
const float worldScale = 10.f;
SampleWindow* window = new SampleWindow("Optix 7 Course Example",
model, camera, worldScale);
window->run();
}
catch (std::runtime_error& e) {
std::cout << GDT_TERMINAL_RED << "FATAL ERROR: " << e.what()
<< GDT_TERMINAL_DEFAULT << std::endl;
exit(1);
}
return 0;
}
在main.cpp中,我们来定义一下场景的最初相机和场景模型。自定义的部分相当简单我就不多赘述了,大家可以根据喜好搭搭积木。
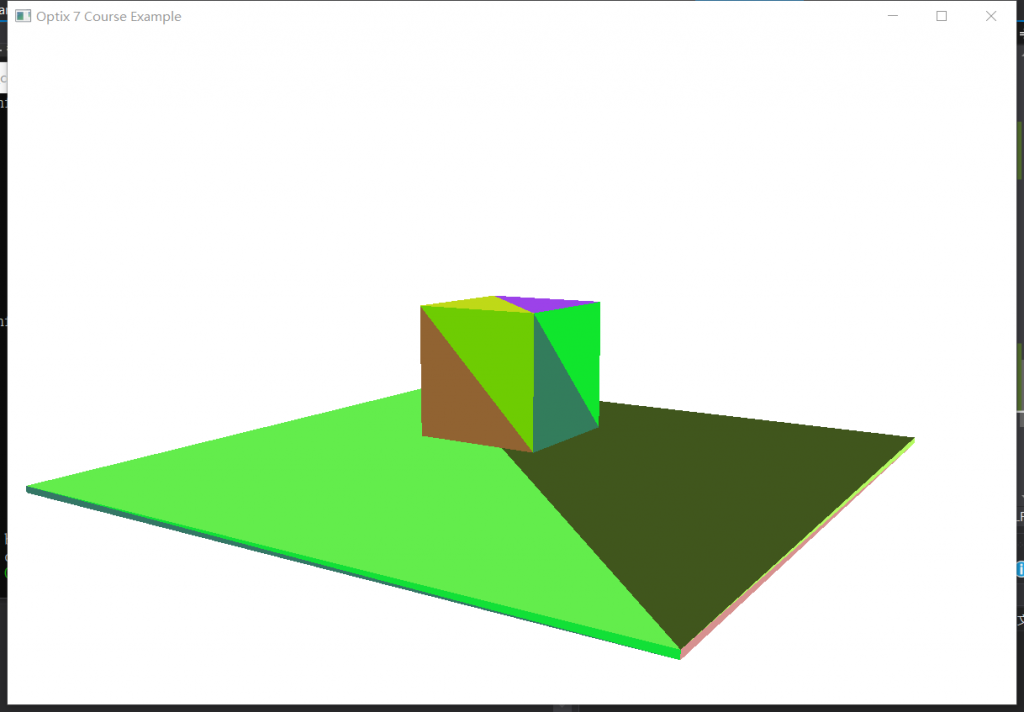
Part.3 多模型多材质的SBT绑定
我们直接跳过example04来复现example05。
考虑一个情境,我们希望第一个立方体的BaseColor是蓝色,第二个立方体的BaseColor是红色,那么我们就需要连续创建两个不同的HitRecord,第一个的data中存一个蓝色像素,第二个的data中存一个红色像素,分别自动与两个立方体绑定,这样在Gpu的ClosetHit Shader中就可以拿到Shader Record中的data从而进行不同颜色的渲染。
然而,我们之前的场景其实只申请了一个TirangleMesh(里面装了两个立方体)。一个TriangleMesh就只能注册成一个物体id,一个物体id就只能绑定一个Shader Record。只有一个Shader Record意味着大家都使用相同的shader实例和传入参数,那么大家都只能用同色材质了。因此,我们必须将不同材质的物体分离为多个模型。下面介绍一下多模型场景的构建。
1、多模型场景
第一步,我们要将两个模型分离到多个TriangleMesh中。同时这意味着我们要向SampleRenderer的构造参数中传递的不再是单mesh,而是meshes[]数组,表示一个场景有多个不同id的物体。
main.cpp:
struct SampleWindow : public GLFCameraWindow
{
SampleWindow(const std::string &title,
const std::vector<TriangleMesh> &model,
const Camera &camera,
const float worldScale)
: GLFCameraWindow(title,camera.from,camera.at,camera.up,worldScale),
sample(model)
{
sample.setCamera(camera);
}
...
extern "C" int main(int ac, char** av)
{
try {
std::vector<TriangleMesh> model(2);
// 100x100 thin ground plane
model[0].addCube(vec3f(0.f, -1.5f, 0.f), vec3f(10.f, .1f, 10.f));
// a unit cube centered on top of that
model[1].addCube(vec3f(0.f, 0.f, 0.f), vec3f(2.f, 2.f, 2.f));
...
我们将model更改为以TriangleMesh为模板的vector容器,向容器中放入了两个不同的立方体。同时要给SampleRenderer添加一个meshes的成员参数,用来装这些模型,构造传参也要改成这个vector。
SampleRenderer.h:
class SampleRenderer
{
public:
SampleRenderer(const std::vector<TriangleMesh>& meshes);
...
std::vector<CUDABuffer> vertexBuffer;
std::vector<CUDABuffer> indexBuffer;
std::vector<TriangleMesh> meshes;
接下来我们修改一下SampleRenderer.cpp,先修改一下构造函数的部分,改成用vector构造;接下来修改一下buildAccel函数,将构造一个物体加速结构 改成 构造一系列物体加速结构。
SampleRenderer.cpp:
SampleRenderer::SampleRenderer(const std::vector<TriangleMesh>& meshes)
: meshes(meshes)
{
initOptix();
...
OptixTraversableHandle SampleRenderer::buildAccel()
{
// meshes.resize(1);
vertexBuffer.resize(meshes.size());
indexBuffer.resize(meshes.size());
OptixTraversableHandle asHandle { 0 };
// ==================================================================
// triangle inputs
// ==================================================================
std::vector<OptixBuildInput> triangleInput(meshes.size());
std::vector<CUdeviceptr> d_vertices(meshes.size());
std::vector<CUdeviceptr> d_indices(meshes.size());
std::vector<uint32_t> triangleInputFlags(meshes.size());
for (int meshID=0;meshID<meshes.size();meshID++) {
// upload the model to the device: the builder
TriangleMesh &model = meshes[meshID];
vertexBuffer[meshID].alloc_and_upload(model.vertex);
indexBuffer[meshID].alloc_and_upload(model.index);
triangleInput[meshID] = {};
triangleInput[meshID].type
= OPTIX_BUILD_INPUT_TYPE_TRIANGLES;
// create local variables, because we need a *pointer* to the
// device pointers
d_vertices[meshID] = vertexBuffer[meshID].d_pointer();
d_indices[meshID] = indexBuffer[meshID].d_pointer();
triangleInput[meshID].triangleArray.vertexFormat = OPTIX_VERTEX_FORMAT_FLOAT3;
triangleInput[meshID].triangleArray.vertexStrideInBytes = sizeof(vec3f);
triangleInput[meshID].triangleArray.numVertices = (int)model.vertex.size();
triangleInput[meshID].triangleArray.vertexBuffers = &d_vertices[meshID];
triangleInput[meshID].triangleArray.indexFormat = OPTIX_INDICES_FORMAT_UNSIGNED_INT3;
triangleInput[meshID].triangleArray.indexStrideInBytes = sizeof(vec3i);
triangleInput[meshID].triangleArray.numIndexTriplets = (int)model.index.size();
triangleInput[meshID].triangleArray.indexBuffer = d_indices[meshID];
triangleInputFlags[meshID] = 0 ;
// in this example we have one SBT entry, and no per-primitive
// materials:
triangleInput[meshID].triangleArray.flags = &triangleInputFlags[meshID];
triangleInput[meshID].triangleArray.numSbtRecords = 1;
triangleInput[meshID].triangleArray.sbtIndexOffsetBuffer = 0;
triangleInput[meshID].triangleArray.sbtIndexOffsetSizeInBytes = 0;
triangleInput[meshID].triangleArray.sbtIndexOffsetStrideInBytes = 0;
}
// ==================================================================
// BLAS setup
// ==================================================================
OptixAccelBuildOptions accelOptions = {};
accelOptions.buildFlags = OPTIX_BUILD_FLAG_NONE
| OPTIX_BUILD_FLAG_ALLOW_COMPACTION
;
accelOptions.motionOptions.numKeys = 1;
accelOptions.operation = OPTIX_BUILD_OPERATION_BUILD;
OptixAccelBufferSizes blasBufferSizes;
OPTIX_CHECK(optixAccelComputeMemoryUsage
(optixContext,
&accelOptions,
triangleInput.data(),
(int)meshes.size(), // num_build_inputs
&blasBufferSizes
));
// ==================================================================
// prepare compaction
// ==================================================================
CUDABuffer compactedSizeBuffer;
compactedSizeBuffer.alloc(sizeof(uint64_t));
OptixAccelEmitDesc emitDesc;
emitDesc.type = OPTIX_PROPERTY_TYPE_COMPACTED_SIZE;
emitDesc.result = compactedSizeBuffer.d_pointer();
// ==================================================================
// execute build (main stage)
// ==================================================================
CUDABuffer tempBuffer;
tempBuffer.alloc(blasBufferSizes.tempSizeInBytes);
CUDABuffer outputBuffer;
outputBuffer.alloc(blasBufferSizes.outputSizeInBytes);
OPTIX_CHECK(optixAccelBuild(optixContext,
/* stream */0,
&accelOptions,
triangleInput.data(),
(int)meshes.size(),
tempBuffer.d_pointer(),
tempBuffer.sizeInBytes,
outputBuffer.d_pointer(),
outputBuffer.sizeInBytes,
&asHandle,
&emitDesc,1
));
CUDA_SYNC_CHECK();
// ==================================================================
// perform compaction
// ==================================================================
uint64_t compactedSize;
compactedSizeBuffer.download(&compactedSize,1);
asBuffer.alloc(compactedSize);
OPTIX_CHECK(optixAccelCompact(optixContext,
/*stream:*/0,
asHandle,
asBuffer.d_pointer(),
asBuffer.sizeInBytes,
&asHandle));
CUDA_SYNC_CHECK();
// ==================================================================
// aaaaaand .... clean up
// ==================================================================
outputBuffer.free(); // << the UNcompacted, temporary output buffer
tempBuffer.free();
compactedSizeBuffer.free();
return asHandle;
}
其实buildAccel的改动量不大,首先这个函数不需要再传模型的参了,直接使用成员参数中的meshes;其余部分就是将原本一个模型的导入和空间申请 全部替换为多个模型的导入和空间申请(包括triangleInput、d_vertices、d_indices等全部由单个变成vector数组),最后调用optixAccelComputeMemoryUsage、optixAccelBuild这些核心api时,强调模型总数即可。
2、多模型的SBT绑定
现在我们拥有了多个TriangleMesh,那么我们SBT中的HitGroupRecord项数也要进行补充。在此之前,我们需要对HitRecord项的结构进行调增。考虑一下,我们要向HitShader中传入哪些参数?因为Shader中要计算光照颜色,那么首先需要法线信息,我们可以传入模型顶点和三角面索引来计算法线;同时还需要基础色信息。因此我们可以把模型顶点、三角面索引、基础色这些信息打包成一个结构体TriangleMeshSBTData,在HitGroupRecord中定义一个TriangleMeshSBTData的data成员参数:
struct TriangleMeshSBTData {
vec3f color;
vec3f *vertex;
vec3i *index;
};
struct __align__( OPTIX_SBT_RECORD_ALIGNMENT ) HitgroupRecord
{
__align__( OPTIX_SBT_RECORD_ALIGNMENT ) char header[OPTIX_SBT_RECORD_HEADER_SIZE];
TriangleMeshSBTData data;
};
在SBT中,我们就对两个立方体分别计算他们的TriangleMeshSBTData,并分别写入两个HitGroupRecord中:
int numObjects = (int)meshes.size();
std::vector<HitgroupRecord> hitgroupRecords;
for (int meshID = 0; meshID < numObjects; meshID++) {
HitgroupRecord rec;
// all meshes use the same code, so all same hit group
OPTIX_CHECK(optixSbtRecordPackHeader(hitgroupPGs[0], &rec));
rec.data.color = gdt::randomColor(meshID);
rec.data.vertex = (vec3f*)vertexBuffer[meshID].d_pointer();
rec.data.index = (vec3i*)indexBuffer[meshID].d_pointer();
hitgroupRecords.push_back(rec);
}
hitgroupRecordsBuffer.alloc_and_upload(hitgroupRecords);
sbt.hitgroupRecordBase = hitgroupRecordsBuffer.d_pointer();
sbt.hitgroupRecordStrideInBytes = sizeof(HitgroupRecord);
sbt.hitgroupRecordCount = (int)hitgroupRecords.size();
对于每一个TriangleMesh创建一个HitgroupRecord,并分别将模型的顶点、三角面索引和随机颜色写入到Record中的data里,然后将他们打包注册即可。
3、着色器
Raygen Shader、Miss Shder和AnyHit Shader都不需要改动,唯一要改的是ClosetHit Shader,相当于编写模型的BSDF着色:
extern "C" __global__ void __closesthit__radiance()
{
const TriangleMeshSBTData &sbtData
= *(const TriangleMeshSBTData*)optixGetSbtDataPointer();
// compute normal:
const int primID = optixGetPrimitiveIndex();
const vec3i index = sbtData.index[primID];
const vec3f &A = sbtData.vertex[index.x];
const vec3f &B = sbtData.vertex[index.y];
const vec3f &C = sbtData.vertex[index.z];
const vec3f Ng = normalize(cross(B-A,C-A));
const vec3f rayDir = optixGetWorldRayDirection();
const float cosDN = 0.2f + .8f*fabsf(dot(rayDir,Ng));
vec3f &prd = *(vec3f*)getPRD<vec3f>();
prd = cosDN * sbtData.color;
}
首先我们在shader中可以直接拿到 求交到的模型所绑定的SBT Record中的data信息,从而拿到vertex、index、color这些信息。调用optixGetPrimitiveIndex()可以得到求交到的三角形编号,index中装的是每个三角形的三个顶点的索引号,就可以取出三个顶点的世界坐标了。通过叉乘便可得到法线,套用经典的lambert光照模型,再乘上data中记录的材质颜色,便完成了该求交点的bsdf计算。
最后,老规矩,编译.cu—parse ptx—编译工程—运行项目:

You may also Like

Optix光线追踪渲染器(五)直接光采样数学推演与实现

Optix光线追踪渲染器(四)路径追踪算法与材质实例
