

Optix光线追踪渲染器(一)硬件光追原理与Optix入门
- 24 3 月, 2023
- by
- pladmin
该工程已经开源:
GitHub – Puluomiyuhun/PL_Tracer: This is a ray tracing renderer based on optimx and cuda.
引言
之前我们使用纯C++写过一个光线追踪渲染器。尽管我们使用了BVH优化求交,并引入了基于cosine项的重要性采样优化,但是跑光追的效率依旧堪忧:当场景引入面数极多的模型、brdf较复杂的材质后,采样数往往需要提升至1000+甚至10000+,这样渲染一张场景图需要数十个小时。这样的渲染时间显然是无法接受的,因此我决定引入杀手锏:将渲染工作从cpu转到gpu上,即将软件光追转化成硬件光追。
提到硬件渲染,大家一定会想到cuda、opengl和dx这些图形接口,本来我想直接套dx的硬件光追,但恰巧最近在看siggragh的时候发现了optix这个宝藏sdk,它对于复杂求交、加速结构和cuda部分的封装十分到位,最重要的是 作者为了照顾新人,编写了一系列optix光追的教程:GitHub – ingowald/optix7course,学习难度曲线相对平缓(乐,实际上也未必简单到哪去,看过官方案例的都知道成熟的optix项目都是cuda+opengl+optix的混合编程)。从本篇博客开始,我会大体按照optix7course的教程进行渲染器的推进,并对于一些代码提出自己的理解和思考;同时会自主引申出自定义场景、相机、复杂材质等教程中没有涉及的内容,从而完成一个功能充足、效率可观的光追渲染器。
Part0. 硬件光追原理
1、光追渲染管线
首先回忆我们之前在C++光追渲染器中描述的软件光追:从相机视口的某个像素发射一根射线,射线与场景中的三角形或层次包围盒(BVH)进行求交,一直找到最近的求交点,然后计算bsdf的着色以及光线的弹射方向;如果没有找到交点,那么就赋予一个底色(一般是环境贴图或是纯色)。
实际上硬件光追的算法逻辑与软件光追无异,同样需要发射射线,需要在场景中快速求交,然后分别讨论求交失败和求交成功找到最近交点的着色情况。不同的是,为了能在硬件GPU上形成高并行的流水计算,硬件光追也定义了一套渲染管线,这套渲染管线上也装载着若干个着色器,从而实现像光栅化渲染管线那样大规模的GPU并行计算。
当然,光追的管线和光栅化的管线差距还是很大的,光追管线上的着色器主要是这五类:
1、RayGen Shader(负责从像素中发射光线,并将该像素的最终结果写回)
2、Miss Shader(处理求交失败时的着色情况)
3、Any Shader(用户定义某个交点是否需要抛弃,比如纯透明物体的求交就没有意义,就需要抛弃)
4、Intersection Shader(定义非三角形形状的求交算法)。
5、Closet Shader(处理最近求交点的着色情况)
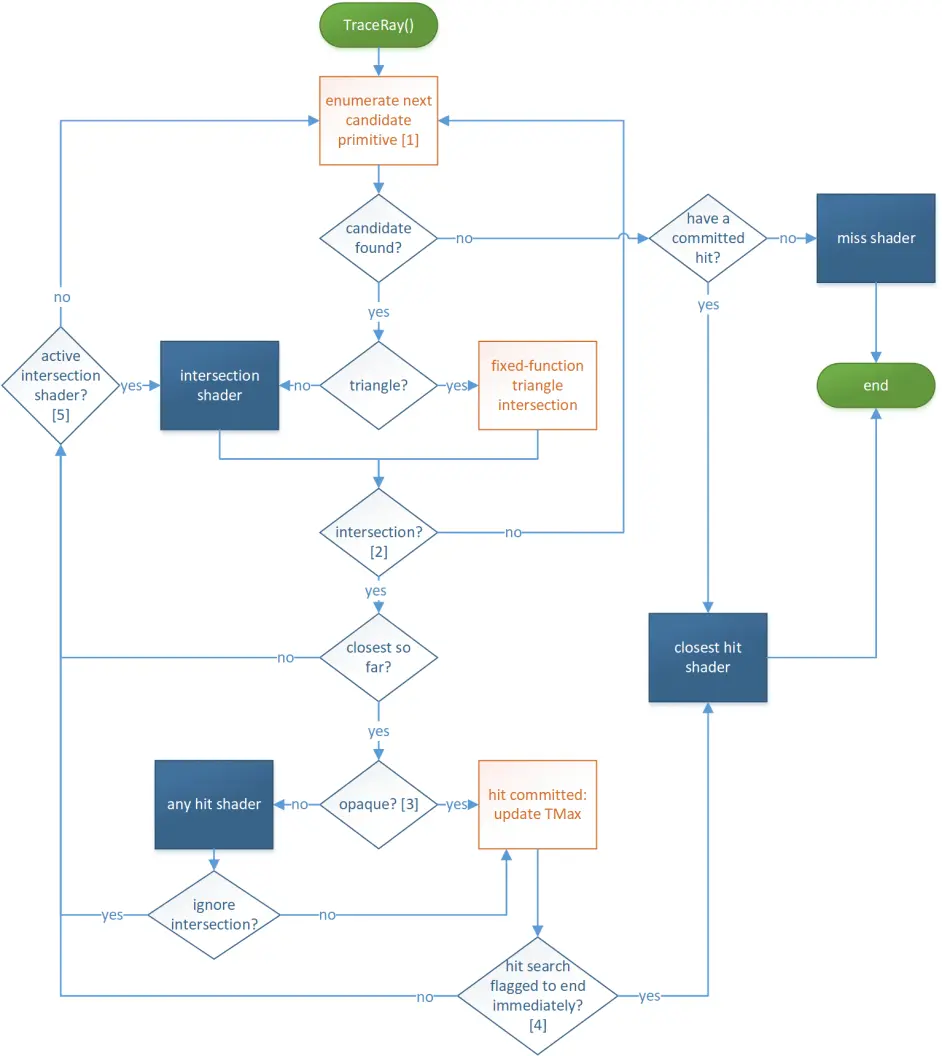
下面用一张示意图来描述这个过程:

上图是一个粗略的逻辑图,我再描述一下这个状态机:RayGen Shader负责创建每个像素出射的光线,然后Optix底层就会开始进行最近点的求交,如果遇到非三角形形状物体就需要Intersection Shader来定义求交规则,每次求交成功了就把求交的点存进Any Hit。Any Hit中定义了用户是否认可这个最近点(有时候用户可能认为某个最近交点不合适,比如透明物体的求交就是无效求交,需要强行抛弃),如果认可该交点,就保存为当前的最近交点。当求交任务完成后检测一下是否有交点,如果没有则调用Miss Shader来渲染求交失败后的颜色;如果有交点则通过Closest Hit得到那个最近交点,并完成求交光线的颜色计算,给出下一次弹射的方向。注意此时的弹射本质上是发射了一根新光线,所以还是通过RayGen Shader来管理发射,然后Optix底层就会进行下一次求交,依次类推……这里的逻辑和之前我们写的c++光追是几乎一样的,只是很多步骤都被封装到着色器里 使用GPU来计算了,这也是Optix等能够把光追效率提升成千上万倍的根本原因。
下图是一个详细的pipeline过程,描述了这几个Shader的逻辑关系:
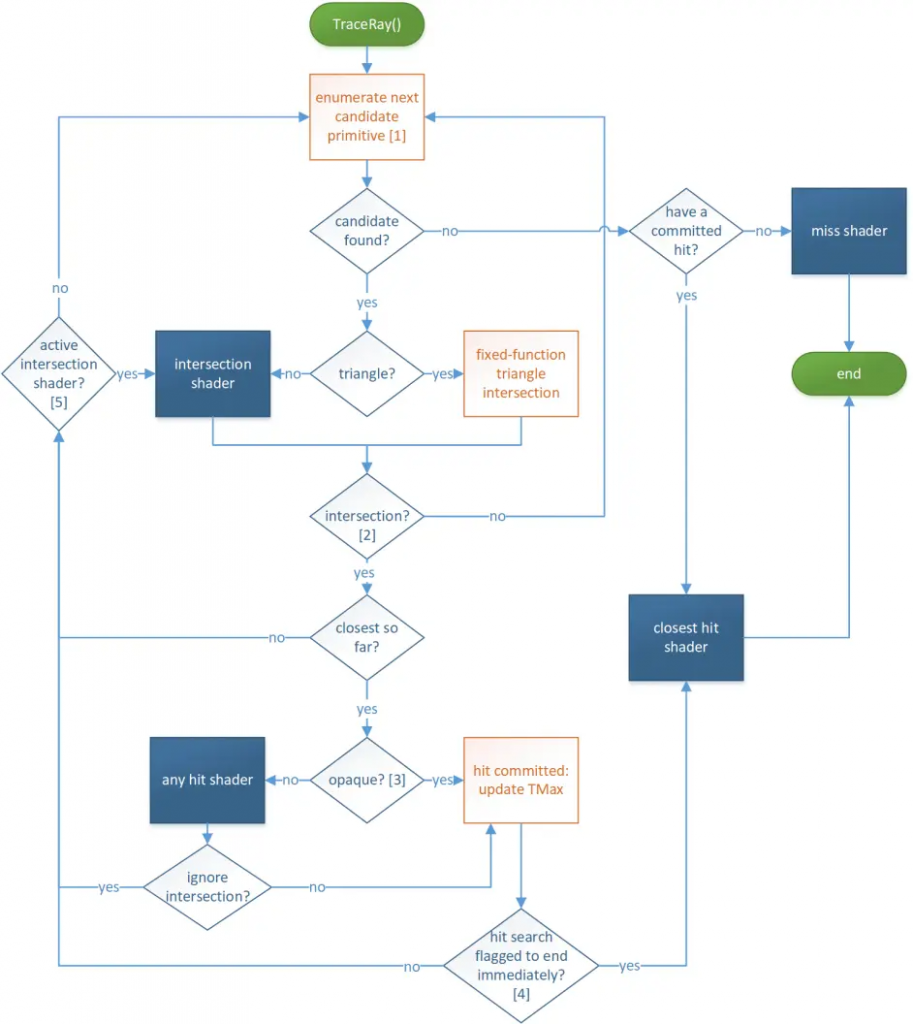
这张图的流程就非常严谨了,不过这张图暂时没有涉及求交的BVH优化这些,还是一个一个图元进行枚举的,不过无伤大雅。我再稍微解释一下这个过程:RayGen发射出一根光线后,Optix封装的底层就会开始依次枚举场景中的图元进行求交测试,每次枚举到图元后,如果它是三角形,就用内置的triangle intersection来求交,如果不是三角形(例如参数球体),就要用用户自定义的intersection shader来定义它的求交算法。如果求交失败,就枚举下一个图元;如果求交成功,对比一下这是不是最近的求交点,如果不是就抛弃,如果是就继续推进:判断图元是不是半透明的,如果是半透明的,那么就需要用户在any hit shader中定义它是否可以被认可为最近求交点,是否要抛弃;如果是不透明的(opaque),那么它就是我们认可的最近求交点,将他保留在hit committed维护(hit committed就是维护最近求交点的,如果发现更近的求交点就会更新)。接下来看一下是否有求交终止的命令,如果有的话就立刻结束一切求交任务,去closet shader计算最近求交点的着色以及弹射光线方向。
2、管线、设备上下文、装载模块
其实大家把上一节那些邪门的着色器换成cpu端的函数,就会发现它和软件光追真的没啥区别,所以过程很好理解。不过既然涉及到硬件,涉及到管线(pipeline),那必然躲不开设备(device)、设备上下文(context)、shader装载模块(module)这些核心概念,我们在建立光追程序时,必须第一时间将管线、设备、设备上下文、装载模块提前全部绑定好。如果没学过dx和opengl估计会对这些概念比较陌生,所以先简单介绍下它们的定义和意义(有请chatGPT登场)

Pipeline就是一个流程概念,描述整个光追过程需要经过哪些着色器或程序,比如将上文提到的四类着色器按流程图连接起来,就得到了一个光追的pipeline。
Device定义我们使用的硬件设备(GPU),而Context就是定义这个设备上要做的操作,以及需要在该设备上存储的数据和资源。Context可以将创建的资源、着色器对象和状态对象绑定到pipeline,也提供了操作设备创建的资源的方法。我们可以理解为Context就是硬件设备的管理员,需要引导硬件做工作、存数据、做交互。
Module就是着色器程序、代码的载体,承载了一段能被GPU处理的着色代码,一般用.Cu文件编译、或PTX汇编编译得到。一般来说,一个Module可以包含多个着色器的代码,每个着色器各自在module绑定一个入口。
其实Pipeline、Context、Module的创建和绑定都比较固定化,后面我们会结合案例慢慢讲怎么应用它们。最后还要介绍一个vulkan和optix特有的一个很重要的数据结构:Shader Binding Table(SBT)。
3、SBT
我们依旧回归软件光追的情境,当光线与某个物体求交成功后,我们就要根据其BSDF来计算光线的着色,这一步就涉及到了程序要根据求交物体 选择其对应的材质实例(以及shader函数)。在软件光追的情境下这件事其实很简单,只需要每个物体都绑定一个材质编号,然后直接根据材质编号寻找对应的shader函数就可以了嘛。
但是硬件光追就麻烦了,首先Closet Hit Shader就是负责计算求交后着色的,所以它本质上就是硬件光追的BSDF Shader。如果场景中有很多不同BSDF的材质实例,意味着管线中要绑很多个对应的Closet Hit Shader。那么当管线求交得到最近点后,它怎么知道要放到哪个Closet Hit Shader去计算呢?以及,它怎么把自己的材质参数(例如base color、roughness等)传入对应的Shader呢?这里就要请出我们的SBT了。SBT记录了管线中所拥有的每一个物体所对应的shader项,以及它要传入的材质参数,这样管线就可以在求交得到最近点后,查阅SBT得到需要调用哪个Shader,以及Shader参数是哪些。
所以SBT的意义就是:一个场景下有很多物体,有很多Shader,不同的物体要用不同的Shader,要给Shader传入不同的材质参数,而SBT就维护了他们之间的映射关系,并储存了要传入的材质参数,这样在跑光追时,管线直接可以通过 求交得到的物体id 以及SBT,计算出要调用哪个hit shader去计算,用什么材质参数去计算BSDF。
上面都是一些通俗易懂的解释,接下来讲一下它的结构:SBT这个数据结构本身存了非常多的槽,每个槽里维护了一个叫Shader Record的东西,每一个Shader Record和场景中的一个物体绑定,用来记录这个物体用的是哪个shader,以及要传入的参数data。Record有三种类型:RayGenerationRecord、HitGroupRecord(可以细分为 Intersection Shader / Any-Hit Shader / Closet-Hit Shader)、MissRecord,分别映射对应的RayGen、Hit、Miss着色器的句柄(表示用的那个shader实例)。optix会根据物体编号直接计算出Shader在SBT中的下标(不需要手动绑定,映射是自动的,1号物体自动绑第一个HitRecord,2号物体绑第二个,以此类推),从而找到对应要调用的Shader。
基础知识差不多就结束了,因为硬件光追比软件光追就复杂在管线、着色器和设备上面了,其他内容都和软件光追差异不大,所以我个人认为软件光追的编程基础+上面补充的硬件管线知识 已经足够我们动手实现硬件光追渲染器了。那么接下来,我们就来配置一下optix,开始代码学习之旅。
Part1. 安装编译Optix
第一节我们先来安装、编译一下optix。因为我是windows党,暂时没有对mac、linux两系统做过测试,因此这二系统的小盆友就自己找一下编译教程了~
首先我们去官网下载optix的sdk轮子:NVIDIA OptiX™ Downloads | NVIDIA Developer,然后将其安装到默认的C:\ProgramData\NVIDIA Corporation\路径中。
接下来打开CMake,source code选择SDK文件夹,where to build选择SDK/build文件夹(新建的),然后分别进行configure、generate:
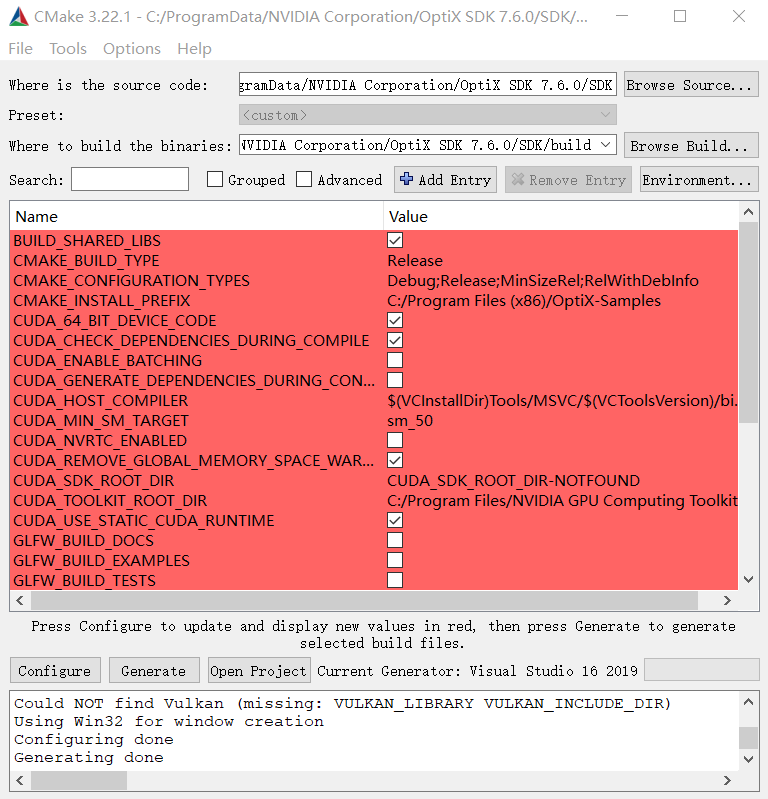
在使用CMake进行configure、generate之后,可以得到适配系统的c++/cuda项目,再点击Open Project,使用vs对生成的项目进行编译,即可得到如下图的一系列文件,这样就是编译完成了。
但是现在还没有结束。因为最新版本的Optix要求较新的显卡驱动版本,我们一直使用的电脑的显卡驱动可能版本过老。这里需要做一个简单的自测:来到C:\ProgramData\NVIDIA Corporation\OptiX SDK 7.6.0\SDK\build\bin\Debug,用cmd打开这里的optixHello.exe,然后观察控制台的结果。
如果结果显示:Caught exception: OPTIX_ERROR_UNSUPPORTED_ABI_VERSION: Optix call ‘optixInit()’ failed,那么恭喜,显卡驱动太旧了,需要在NVIDIA官网搜索自己显卡驱动,选择最新的版本号并安装。
如果显卡版本达到了Optix的需求,运行optixHello.exe后顺利出现了一个纯色窗口,那么恭喜,这下optix的编译安装完全成功了。
Part.2 安装编译辅助模块
除了optix以外,官方还提供了一些辅助光追的模块,例如gdt(辅助验证调试/数学模块)、glfWindow(窗口模块)、stb_image(加载图片模块)、tiny_onj_loader(加载obj模型模块)等等,具体链接见optix7course/common at master · ingowald/optix7course · GitHub
其实我建议大家直接把github的各个example也全部拷下来,因为有一些例如optix7.h、CUDABuffer.h这些和optix、cuda底层相关的比较常用的头文件分散在了各个example里,到时候我们复现example的时候可能需要直接把这些底层头文件复制过来用。
Part.3 配置VS项目环境
现在我们开始准备第一个测试项目。首先我们创建一个新的Visual Studio项目,模板选择空项目,先创建一个空白的main.cpp文件,然后将官方github的example01里面配套的 optix7.h 和 辅助模块中gdt文件夹放到main.cpp同目录下。
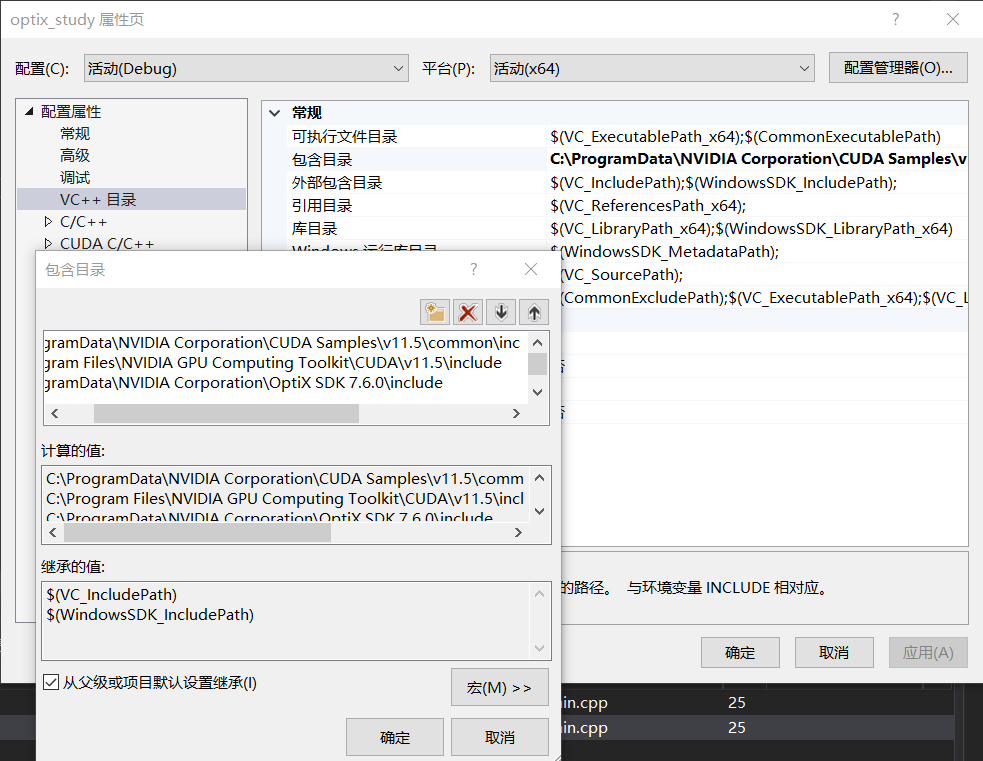
接下来我们配置一下项目的环境,步骤比较繁多请一定要耐心。右键项目-属性-VC++目录-包含目录,添加optix的include目录、cuda的include目录:
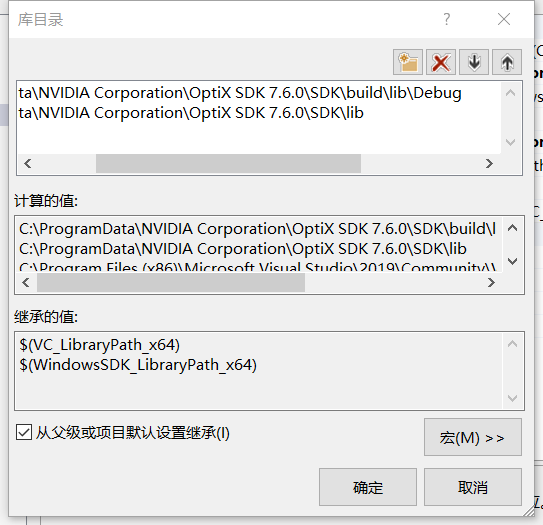
然后找到VC++目录-库目录,添加optix的lib目录、cuda的lib目录、opengl的lib目录:
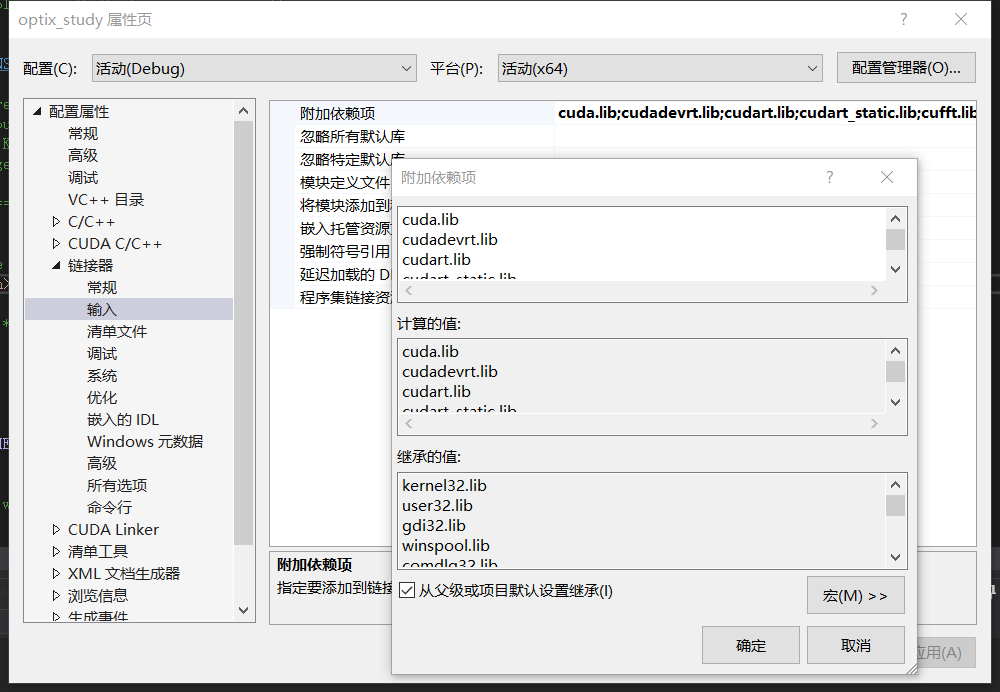
然后找到链接器-输入-附加依赖项,添加OpenGL32.lib、cuda.lib、cudadevrt.lib、cudart.lib、cudart_static.lib、cufft.lib、cufftw.lib、curand.lib、cusolver.lib、cusparse.lib、nvblas.lib,当然实际上最需要添加的只有cuda.lib,其他的未必用得上,只是预防万一后面用到了再手忙脚乱。
接下来配置一下cuda依赖项,右键项目-属性-生成依赖性-生成自定义,把你的cuda勾选上:

最后右键项目-属性-CUDA C/C++-Common,把Compiler Output的后缀改成ptx;Include Directories增加一下opentix的include文件夹;NVCC编译类型改成编译ptx;目标机型改成64位:
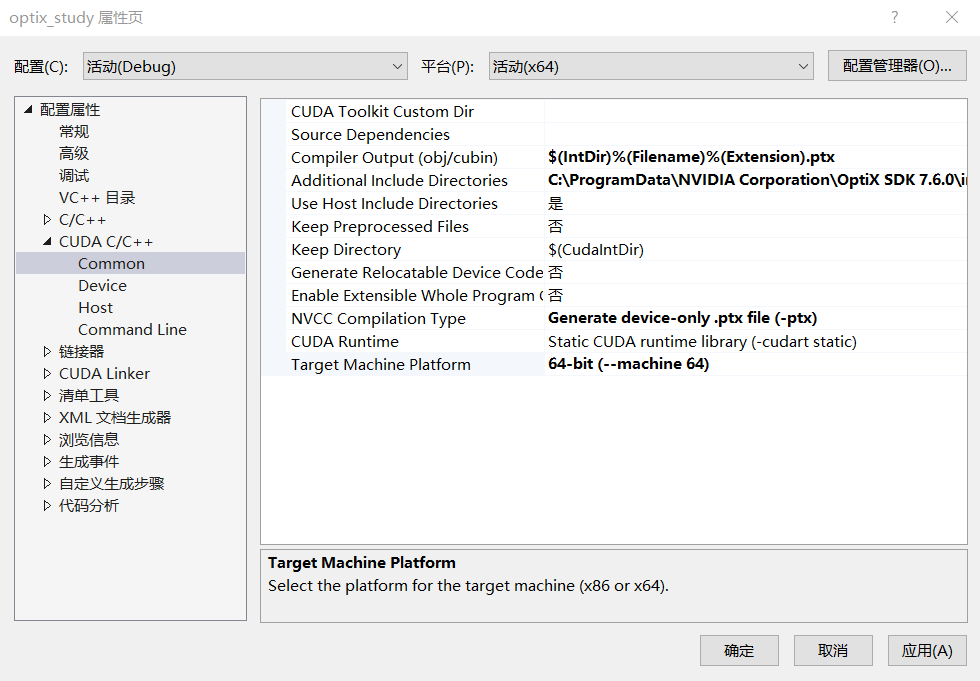
到此环境就配置好了。这里我踩了无数个坑,所以特意整理了一下,希望读者配置环境能够一气呵成。
Part4. 测试项目
现在我们可以开始运行第一个示例项目example01了。这个项目其实只是为了检测cuda和optix是否配置成功,没有任何实质意义,因此我们直接上main.cpp的代码:
// common gdt helper tools
#include "gdt/gdt.h"
#include "optix7.h"
/*! \namespace osc - Optix Siggraph Course */
namespace osc {
/*! helper function that initializes optix and checks for errors */
void initOptix()
{
// -------------------------------------------------------
// check for available optix7 capable devices
// -------------------------------------------------------
cudaFree(0);
int numDevices;
cudaGetDeviceCount(&numDevices);
if (numDevices == 0)
throw std::runtime_error("#osc: no CUDA capable devices found!");
std::cout << "#osc: found " << numDevices << " CUDA devices" << std::endl;
// -------------------------------------------------------
// initialize optix
// -------------------------------------------------------
OPTIX_CHECK(optixInit());
}
/*! main entry point to this example - initially optix, print hello
world, then exit */
extern "C" int main(int ac, char** av)
{
try {
std::cout << "#osc: initializing optix..." << std::endl;
initOptix();
std::cout << GDT_TERMINAL_GREEN
<< "#osc: successfully initialized optix... yay!"
<< GDT_TERMINAL_DEFAULT << std::endl;
// for this simple hello-world example, don't do anything else
// ...
std::cout << "#osc: done. clean exit." << std::endl;
}
catch (std::runtime_error& e) {
std::cout << GDT_TERMINAL_RED << "FATAL ERROR: " << e.what()
<< GDT_TERMINAL_DEFAULT << std::endl;
exit(1);
}
return 0;
}
}
代码不难分析,在main函数中调用了initOptix()函数,然后用try-catch结构监测各个模块是否有错误。initOptix函数主要对cuda进行了内存初始化、检测gpu设备、optix内核启动测试,如果一切正常,那么运行后可以得到如下结果:

如果得到的是 Optix call ‘optixInit()’ failed这样的报错,说明显卡驱动太老了,请参考前文的解决办法;如果得到的是no CUDA capable devices found这样的报错,说明电脑没装cuda或者cuda的环境变量配置有问题。
Part5. Optix基本架构搭建
0、准备工作
现在我们来复现一下example02。作者说example02跨度很大,难度有个飞跃,所以我提前阅读了一下example02的代码,结果发现example02这节搭建了一个完整的optix光追架构,像设备、设备上下文、【RayGen、Miss、HitGroup】着色器、装载模块、管线等一应俱全,也绑定了SBT。所以想要顺利理解example02,就需要大家把Part0的硬件光追原理部分理解一下,这样才能在后面不犯懵。
首先我们把3rdParty文件夹复制过来,再把example02里的CUDABuffer.h直接拷到工程里,这部分是cuda的内存管理、上传下载逻辑,我们没有复现和分析这个代码的必要,直接当黑盒用。
1、缓冲区定义
接下来我们创建一个LaunchParams.h,这个文件是定义了一个缓冲区结构体,管线会不断将光追结果写入这个结构体。
#include "gdt/math/vec.h"
namespace osc {
using namespace gdt;
struct LaunchParams
{
int frameID { 0 };
uint32_t *colorBuffer;
vec2i fbSize;
};
}
LaunchParams结构体的内容比较好理解,frameID就是代表这是几号缓冲区(光栅化渲染器那节讲过双缓冲的概念,可以回忆一下),colorBuffer就是记录光追后的颜色结果,fbSize就是渲染结果的宽高尺寸,用到了gdt库内的二维向量类型。这部分很短,不多赘述。
2、着色器代码
接下来我们创建一个devicePrograms.cu,他就是我们要写的着色器代码。之所以是.cu后缀,是因为要依靠cuda把着色器代码编译成可以装载进module让gpu运行的机器码。我们编写一下着色器的代码:
#include <optix_device.h>
#include "LaunchParams.h"
using namespace osc;
namespace osc {
extern "C" __constant__ LaunchParams optixLaunchParams;
extern "C" __global__ void __closesthit__radiance()
{ /*! for this simple example, this will remain empty */ }
extern "C" __global__ void __anyhit__radiance()
{ /*! for this simple example, this will remain empty */ }
extern "C" __global__ void __miss__radiance()
{ /*! for this simple example, this will remain empty */ }
extern "C" __global__ void __raygen__renderFrame()
{
if (optixLaunchParams.frameID == 0 &&
optixGetLaunchIndex().x == 0 &&
optixGetLaunchIndex().y == 0) {
// we could of course also have used optixGetLaunchDims to query
// the launch size, but accessing the optixLaunchParams here
// makes sure they're not getting optimized away (because
// otherwise they'd not get used)
printf("############################################\n");
printf("Hello world from OptiX 7 raygen program!\n(within a %ix%i-sized launch)\n",
optixLaunchParams.fbSize.x,
optixLaunchParams.fbSize.y);
printf("############################################\n");
}
const int ix = optixGetLaunchIndex().x;
const int iy = optixGetLaunchIndex().y;
const int r = (ix % 256);
const int g = (iy % 256);
const int b = ((ix+iy) % 256);
const uint32_t rgba = 0xff000000
| (r<<0) | (g<<8) | (b<<16);
const uint32_t fbIndex = ix+iy*optixLaunchParams.fbSize.x;
optixLaunchParams.colorBuffer[fbIndex] = rgba;
}
}
上面就是我们要写入的着色器代码。首先我们的着色器要定义缓冲区,所以需要引用一下我们前面的LaunchParams.h,然后用它定义了一个用于输出光追结果的缓冲区optixLaunchParams。
接下来就定义了四个光追着色器——RayGen、Miss、AnyHit、ClosestHit(对于没有复杂形状的场景,无需定义IntersectionHit),因为example02实际上不发射射线,也没什么求交问题,只是想直接向缓冲区写回颜色,因此Hit、Miss着色器都直接留空,只有RayGen着色器需要编写 写回颜色的代码。
RayGen的代码意思比较明确,optixGetLaunchIndex()获取的就是当前视口的像素坐标,ix、iy分别是当前像素的横纵坐标,通过坐标值来计算r、g、b的值,最后存入到一个32位的变量中,写入optixLaunchParams这个缓冲区中的对应位置。
好了,着色器代码就写完了,此时我们需要点击一下编译。可能会有人问:为什么现在点编译,不等其他文件的代码写完再一起编译呢?这是因为我们后面创建Module的时候,需要直接把着色器代码编译后的机器码喂进去,因此在创建管线、模块之前,我们需要提前拿到.cu文件编译后的机器码。点击编译,便可以在 项目名称\x64\Debug的路径下找到devicePrograms.cu.ptx,这个就是着色器的GPU端机器码。我们可以用winhex看一下它的内容:
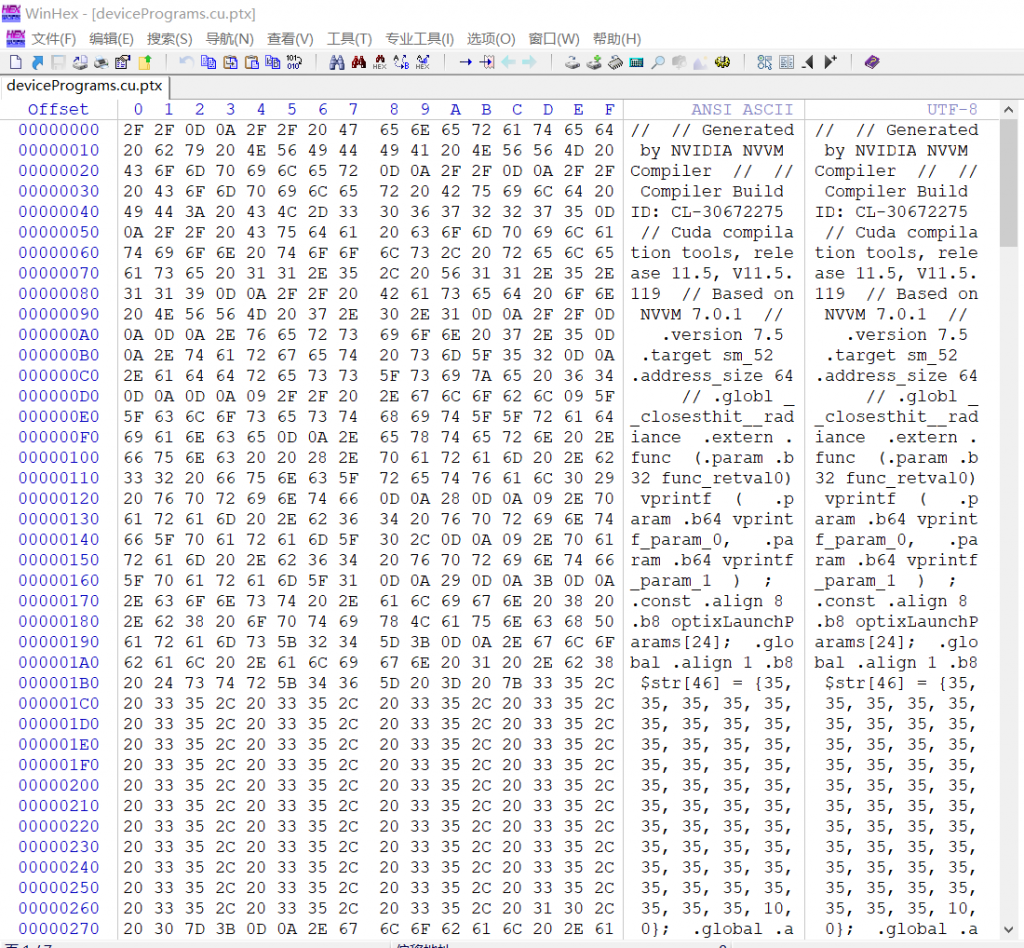
可以看到这段GPU机器码包含了你的显卡驱动信息、cuda套件信息、编译器信息,以及定义的各种变量、结构体、函数、寄存器调用等等(甚至还有乱七八糟的注释)。
但是还没完,因为后文我们的渲染器cpp无法直接读取ptx文件,他只能读取char[]形式的机器码。因此接下来我们需要写个简单的python脚本,把这段ptx机器码给embedding成c语言char[]的形式,然后写入到一个叫MyShader.c的文件中去,这样后续的渲染器cpp就可以直接获得char[]形式的机器码了。
f = open("D:/cg_optix/optix_study/optix_study/x64/Debug/devicePrograms.cu.ptx", 'rb', True)
w = open("D:/cg_optix/optix_study/optix_study/x64/Debug/MyShader.c",'w',True)
w.write("#ifdef __cplusplus\nextern \"C\" {\n#endif\n")
w.write("const unsigned char embedded_ptx_code[] = {\n")
k = 1
while True:
ch = f.read(1)
if not ch: break
w.write('0x{:02X}'.format(int.from_bytes(ch, byteorder='big', signed=False)))
w.write(",")
if k % 16 == 0:
w.write("\n")
k += 1
f.close()
w.write("};\n#ifdef __cplusplus\n}\n#endif")
运行上述python脚本后,我们就得到了如下图形式的着色器机器码。

3、创建渲染器架构
最重量级的内容终于来了,那就是我们要开始创建渲染器的整体架构了。首先创建SampleRenderer.h作为类的头文件,代码如下:
#include "CUDABuffer.h"
#include "LaunchParams.h"
/*! \namespace osc - Optix Siggraph Course */
namespace osc {
/*! a sample OptiX-7 renderer that demonstrates how to set up
context, module, programs, pipeline, SBT, etc, and perform a
valid launch that renders some pixel (using a simple test
pattern, in this case */
class SampleRenderer
{
// ------------------------------------------------------------------
// publicly accessible interface
// ------------------------------------------------------------------
public:
/*! constructor - performs all setup, including initializing
optix, creates module, pipeline, programs, SBT, etc. */
SampleRenderer();
/*! render one frame */
void render();
/*! resize frame buffer to given resolution */
void resize(const vec2i &newSize);
/*! download the rendered color buffer */
void downloadPixels(uint32_t h_pixels[]);
protected:
// ------------------------------------------------------------------
// internal helper functions
// ------------------------------------------------------------------
/*! helper function that initializes optix and checks for errors */
void initOptix();
/*! creates and configures a optix device context (in this simple
example, only for the primary GPU device) */
void createContext();
/*! creates the module that contains all the programs we are going
to use. in this simple example, we use a single module from a
single .cu file, using a single embedded ptx string */
void createModule();
/*! does all setup for the raygen program(s) we are going to use */
void createRaygenPrograms();
/*! does all setup for the miss program(s) we are going to use */
void createMissPrograms();
/*! does all setup for the hitgroup program(s) we are going to use */
void createHitgroupPrograms();
/*! assembles the full pipeline of all programs */
void createPipeline();
/*! constructs the shader binding table */
void buildSBT();
protected:
/*! @{ CUDA device context and stream that optix pipeline will run
on, as well as device properties for this device */
CUcontext cudaContext;
CUstream stream;
cudaDeviceProp deviceProps;
/*! @} */
//! the optix context that our pipeline will run in.
OptixDeviceContext optixContext;
/*! @{ the pipeline we're building */
OptixPipeline pipeline;
OptixPipelineCompileOptions pipelineCompileOptions = {};
OptixPipelineLinkOptions pipelineLinkOptions = {};
/*! @} */
/*! @{ the module that contains out device programs */
OptixModule module;
OptixModuleCompileOptions moduleCompileOptions = {};
/* @} */
/*! vector of all our program(group)s, and the SBT built around
them */
std::vector<OptixProgramGroup> raygenPGs;
CUDABuffer raygenRecordsBuffer;
std::vector<OptixProgramGroup> missPGs;
CUDABuffer missRecordsBuffer;
std::vector<OptixProgramGroup> hitgroupPGs;
CUDABuffer hitgroupRecordsBuffer;
OptixShaderBindingTable sbt = {};
/*! @{ our launch parameters, on the host, and the buffer to store
them on the device */
LaunchParams launchParams;
CUDABuffer launchParamsBuffer;
/*! @} */
CUDABuffer colorBuffer;
};
}
可以看到渲染器拥有很多变量和套件,包括管线、设备、上下文、装载模块、着色器程序组,以及用于交换的缓冲区。直接对着头文件的定义讲不是什么好的选择,所以接下来我们结合SampleRenderer.cpp的内容来对架构进行逐层分析。首先我们看前面部分:
#include "SampleRenderer.h"
// this include may only appear in a single source file:
#include <optix_function_table_definition.h>
/*! \namespace osc - Optix Siggraph Course */
namespace osc {
extern "C" char embedded_ptx_code[];
/*! SBT record for a raygen program */
struct __align__( OPTIX_SBT_RECORD_ALIGNMENT ) RaygenRecord
{
__align__( OPTIX_SBT_RECORD_ALIGNMENT ) char header[OPTIX_SBT_RECORD_HEADER_SIZE];
// just a dummy value - later examples will use more interesting
// data here
void *data;
};
/*! SBT record for a miss program */
struct __align__( OPTIX_SBT_RECORD_ALIGNMENT ) MissRecord
{
__align__( OPTIX_SBT_RECORD_ALIGNMENT ) char header[OPTIX_SBT_RECORD_HEADER_SIZE];
// just a dummy value - later examples will use more interesting
// data here
void *data;
};
/*! SBT record for a hitgroup program */
struct __align__( OPTIX_SBT_RECORD_ALIGNMENT ) HitgroupRecord
{
__align__( OPTIX_SBT_RECORD_ALIGNMENT ) char header[OPTIX_SBT_RECORD_HEADER_SIZE];
// just a dummy value - later examples will use more interesting
// data here
int objectID;
};
首先这里定义了一个embedded_ptx_code,这个就是要装 我们用.cu文件编译出来的ptx机器码,可以直接extern到刚才创建的MyShader.c中,直接拿到这串char[]形式的机器码。
然后它定义了RaygenRecord、MissRecord、HitgroupRecord,还记得Record是什么意思吗?就是SBT里面维护的着色器记录项,用来和场景中的材质实例做映射绑定的。由于Record对于字节对齐要求很高,所以用到了__align__关键字;每个record都有一个header表示该着色器实例的句柄。由于一个场景中只需要一个RaygenRecord和一个MissRecord,所以他们内部直接声明场景数据即可,即void *data;而HitRecord可能会有若干个,分别对应不同的物体或材质,所以他们内部需要声明一个int objectID,表示当前的HitRecord绑定的是几号物体/材质。
SampleRenderer::SampleRenderer()
{
initOptix();
std::cout << "#osc: creating optix context ..." << std::endl;
createContext();
std::cout << "#osc: setting up module ..." << std::endl;
createModule();
std::cout << "#osc: creating raygen programs ..." << std::endl;
createRaygenPrograms();
std::cout << "#osc: creating miss programs ..." << std::endl;
createMissPrograms();
std::cout << "#osc: creating hitgroup programs ..." << std::endl;
createHitgroupPrograms();
std::cout << "#osc: setting up optix pipeline ..." << std::endl;
createPipeline();
std::cout << "#osc: building SBT ..." << std::endl;
buildSBT();
launchParamsBuffer.alloc(sizeof(launchParams));
std::cout << "#osc: context, module, pipeline, etc, all set up ..." << std::endl;
std::cout << GDT_TERMINAL_GREEN;
std::cout << "#osc: Optix 7 Sample fully set up" << std::endl;
std::cout << GDT_TERMINAL_DEFAULT;
}
上面这部分是SampleRenderer的构造函数,其实就是初始化optix、绑定设备上下文、创建着色器承载模块、创建各个着色器实例(注意这个实例指的是一个过程实体,不是着色器代码。着色器代码在之前写的.cu文件中)、将这些着色器程序绑定进渲染管线、创建SBT表,然后渲染器的架构就搭建完成了。接下来我们逐个分析这个构造过程。
void SampleRenderer::initOptix()
{
std::cout << "#osc: initializing optix..." << std::endl;
cudaFree(0);
int numDevices;
cudaGetDeviceCount(&numDevices);
if (numDevices == 0)
throw std::runtime_error("#osc: no CUDA capable devices found!");
std::cout << "#osc: found " << numDevices << " CUDA devices" << std::endl;
OPTIX_CHECK( optixInit() );
std::cout << GDT_TERMINAL_GREEN
<< "#osc: successfully initialized optix... yay!"
<< GDT_TERMINAL_DEFAULT << std::endl;
}
static void context_log_cb(unsigned int level,
const char *tag,
const char *message,
void *)
{
fprintf( stderr, "[%2d][%12s]: %s\n", (int)level, tag, message );
}
optix初始化,就是寻找gpu、检测显卡驱动版本、启动optix内核这些操作,在example01里面已经做过了,不再赘述;后面有一个context_log_cb是debug用的,也没什么解读的意义。
void SampleRenderer::createContext()
{
// for this sample, do everything on one device
const int deviceID = 0;
CUDA_CHECK(SetDevice(deviceID));
CUDA_CHECK(StreamCreate(&stream));
cudaGetDeviceProperties(&deviceProps, deviceID);
std::cout << "#osc: running on device: " << deviceProps.name << std::endl;
CUresult cuRes = cuCtxGetCurrent(&cudaContext);
if( cuRes != CUDA_SUCCESS )
fprintf( stderr, "Error querying current context: error code %d\n", cuRes );
OPTIX_CHECK(optixDeviceContextCreate(cudaContext, 0, &optixContext));
OPTIX_CHECK(optixDeviceContextSetLogCallback
(optixContext,context_log_cb,nullptr,4));
}
创建设备上下文。首先我们要确定这个程序绑定的设备是哪个,一般都是0号设备;创建一个数据流stream,用于设备的数据交互。接下来,我们要获得Cuda自身的上下文——指的是Cuda自带的一套 管理自己行为和数据的cudaContext,由于optix有一套自己编写的指挥逻辑,因此optix会将cudaContext拿出来,然后套换成自己的optixContext。这样optix就可以根据自定义的逻辑来管理Cuda的行为和数据了。(当然Context上下文这个概念过于抽象,不理解也问题不大,毕竟这些都是架构写死的代码了)
void SampleRenderer::createModule()
{
moduleCompileOptions.maxRegisterCount = 50;
moduleCompileOptions.optLevel = OPTIX_COMPILE_OPTIMIZATION_DEFAULT;
moduleCompileOptions.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_NONE;
pipelineCompileOptions = {};
pipelineCompileOptions.traversableGraphFlags = OPTIX_TRAVERSABLE_GRAPH_FLAG_ALLOW_SINGLE_GAS;
pipelineCompileOptions.usesMotionBlur = false;
pipelineCompileOptions.numPayloadValues = 2;
pipelineCompileOptions.numAttributeValues = 2;
pipelineCompileOptions.exceptionFlags = OPTIX_EXCEPTION_FLAG_NONE;
pipelineCompileOptions.pipelineLaunchParamsVariableName = "optixLaunchParams";
pipelineLinkOptions.maxTraceDepth = 2;
const std::string ptxCode = embedded_ptx_code;
char log[2048];
size_t sizeof_log = sizeof( log );
OPTIX_CHECK(optixModuleCreateFromPTX(optixContext,
&moduleCompileOptions,
&pipelineCompileOptions,
ptxCode.c_str(),
ptxCode.size(),
log,&sizeof_log,
&module
));
if (sizeof_log > 1) PRINT(log);
}
创建着色器载体模块。这里我们可以看到,embedded_ptx_code(即前面我们编译出来的着色器机器码)被绑定在了Module身上,同时我们在.cu文件里定义的“optixLaunchParams”会被置为光追的最终输出。如此,我们的着色器机器码以Module为媒介 成功和管线取得了绑定。
void SampleRenderer::createRaygenPrograms()
{
// we do a single ray gen program in this example:
raygenPGs.resize(1);
OptixProgramGroupOptions pgOptions = {};
OptixProgramGroupDesc pgDesc = {};
pgDesc.kind = OPTIX_PROGRAM_GROUP_KIND_RAYGEN;
pgDesc.raygen.module = module;
pgDesc.raygen.entryFunctionName = "__raygen__renderFrame";
// OptixProgramGroup raypg;
char log[2048];
size_t sizeof_log = sizeof( log );
OPTIX_CHECK(optixProgramGroupCreate(optixContext,
&pgDesc,
1,
&pgOptions,
log,&sizeof_log,
&raygenPGs[0]
));
if (sizeof_log > 1) PRINT(log);
}
/*! does all setup for the miss program(s) we are going to use */
void SampleRenderer::createMissPrograms()
{
// we do a single ray gen program in this example:
missPGs.resize(1);
OptixProgramGroupOptions pgOptions = {};
OptixProgramGroupDesc pgDesc = {};
pgDesc.kind = OPTIX_PROGRAM_GROUP_KIND_MISS;
pgDesc.miss.module = module;
pgDesc.miss.entryFunctionName = "__miss__radiance";
// OptixProgramGroup raypg;
char log[2048];
size_t sizeof_log = sizeof( log );
OPTIX_CHECK(optixProgramGroupCreate(optixContext,
&pgDesc,
1,
&pgOptions,
log,&sizeof_log,
&missPGs[0]
));
if (sizeof_log > 1) PRINT(log);
}
/*! does all setup for the hitgroup program(s) we are going to use */
void SampleRenderer::createHitgroupPrograms()
{
// for this simple example, we set up a single hit group
hitgroupPGs.resize(1);
OptixProgramGroupOptions pgOptions = {};
OptixProgramGroupDesc pgDesc = {};
pgDesc.kind = OPTIX_PROGRAM_GROUP_KIND_HITGROUP;
pgDesc.hitgroup.moduleCH = module;
pgDesc.hitgroup.entryFunctionNameCH = "__closesthit__radiance";
pgDesc.hitgroup.moduleAH = module;
pgDesc.hitgroup.entryFunctionNameAH = "__anyhit__radiance";
char log[2048];
size_t sizeof_log = sizeof( log );
OPTIX_CHECK(optixProgramGroupCreate(optixContext,
&pgDesc,
1,
&pgOptions,
log,&sizeof_log,
&hitgroupPGs[0]
));
if (sizeof_log > 1) PRINT(log);
}
接下来就是创建管线中的着色器实例。要声明各类着色器分别有几个,对应的是哪个module,各个着色器在module中着色器机器码的入口函数是什么,最后靠optixProgramGroupCreate函数来得到一个定义完全的着色器实例。
void SampleRenderer::createPipeline()
{
std::vector<OptixProgramGroup> programGroups;
for (auto pg : raygenPGs)
programGroups.push_back(pg);
for (auto pg : missPGs)
programGroups.push_back(pg);
for (auto pg : hitgroupPGs)
programGroups.push_back(pg);
char log[2048];
size_t sizeof_log = sizeof( log );
OPTIX_CHECK(optixPipelineCreate(optixContext,
&pipelineCompileOptions,
&pipelineLinkOptions,
programGroups.data(),
(int)programGroups.size(),
log,&sizeof_log,
&pipeline
));
if (sizeof_log > 1) PRINT(log);
OPTIX_CHECK(optixPipelineSetStackSize
(/* [in] The pipeline to configure the stack size for */
pipeline,
/* [in] The direct stack size requirement for direct
callables invoked from IS or AH. */
2*1024,
/* [in] The direct stack size requirement for direct
callables invoked from RG, MS, or CH. */
2*1024,
/* [in] The continuation stack requirement. */
2*1024,
/* [in] The maximum depth of a traversable graph
passed to trace. */
1));
if (sizeof_log > 1) PRINT(log);
}
当着色器实例定义好后,就需要将他们串联进管线。这里就是把所有着色器依次连接到programGroups中,根据这个架构创建出一个完整的pipeline,最后再对pipeline进行栈的申请(申请出来要存什么数据我没看懂,有无大佬指教一下这IS、AH、RG、MS、CH都是些啥…)
void SampleRenderer::buildSBT()
{
// ------------------------------------------------------------------
// build raygen records
// ------------------------------------------------------------------
std::vector<RaygenRecord> raygenRecords;
for (int i=0;i<raygenPGs.size();i++) {
RaygenRecord rec;
OPTIX_CHECK(optixSbtRecordPackHeader(raygenPGs[i],&rec));
rec.data = nullptr; /* for now ... */
raygenRecords.push_back(rec);
}
raygenRecordsBuffer.alloc_and_upload(raygenRecords);
sbt.raygenRecord = raygenRecordsBuffer.d_pointer();
// ------------------------------------------------------------------
// build miss records
// ------------------------------------------------------------------
std::vector<MissRecord> missRecords;
for (int i=0;i<missPGs.size();i++) {
MissRecord rec;
OPTIX_CHECK(optixSbtRecordPackHeader(missPGs[i],&rec));
rec.data = nullptr; /* for now ... */
missRecords.push_back(rec);
}
missRecordsBuffer.alloc_and_upload(missRecords);
sbt.missRecordBase = missRecordsBuffer.d_pointer();
sbt.missRecordStrideInBytes = sizeof(MissRecord);
sbt.missRecordCount = (int)missRecords.size();
// ------------------------------------------------------------------
// build hitgroup records
// ------------------------------------------------------------------
// we don't actually have any objects in this example, but let's
// create a dummy one so the SBT doesn't have any null pointers
// (which the sanity checks in compilation would complain about)
int numObjects = 1;
std::vector<HitgroupRecord> hitgroupRecords;
for (int i=0;i<numObjects;i++) {
int objectType = 0;
HitgroupRecord rec;
OPTIX_CHECK(optixSbtRecordPackHeader(hitgroupPGs[objectType],&rec));
rec.objectID = i;
hitgroupRecords.push_back(rec);
}
hitgroupRecordsBuffer.alloc_and_upload(hitgroupRecords);
sbt.hitgroupRecordBase = hitgroupRecordsBuffer.d_pointer();
sbt.hitgroupRecordStrideInBytes = sizeof(HitgroupRecord);
sbt.hitgroupRecordCount = (int)hitgroupRecords.size();
}
最后我们要绑定一下SBT。在SampleRenderer.cpp的开头定义了若干个Record项,这里我们就需要枚举所有着色器实例,通过optixSbtRecordPackHeader获得这些着色器实例的header(句柄),然后分别分析data、objectID怎么赋值,得到每个着色器实例对应的Record。最后将这几个类别的Record分别注册到SBT里,这样SBT就构建好了,未来场景中求交成功后直接访问SBT就可以知道该物体/材质要调用哪个着色器实例,然后再根据该着色器实例所绑定的装载模块和入口函数,便可直接执行对应的shader代码。
如此,构造函数就结束了。我们总结一下这个架构:首先我们的程序在0号设备(gpu)上运作,创建了一个管理人员optixContext指挥硬件工作。然后我们写了着色器代码,将其编译成ptx机器码绑定到一个Module中;接下来创建了若干个着色器实例,每个着色器实例都和Module模块装载的ptx机器码中的一个入口函数绑定;创建了一个管线将这些着色器实例串联了起来;最后创建了一个SBT,用来定义场景中不同物体/材质与各个着色器实例之间的绑定关系。
构造完成后,就可以定义我们的渲染函数了:
void SampleRenderer::render()
{
// sanity check: make sure we launch only after first resize is
// already done:
if (launchParams.fbSize.x == 0) return;
launchParamsBuffer.upload(&launchParams,1);
launchParams.frameID++;
OPTIX_CHECK(optixLaunch(/*! pipeline we're launching launch: */
pipeline,stream,
/*! parameters and SBT */
launchParamsBuffer.d_pointer(),
launchParamsBuffer.sizeInBytes,
&sbt,
/*! dimensions of the launch: */
launchParams.fbSize.x,
launchParams.fbSize.y,
1
));
// sync - make sure the frame is rendered before we download and
// display (obviously, for a high-performance application you
// want to use streams and double-buffering, but for this simple
// example, this will have to do)
CUDA_SYNC_CHECK();
}
/*! resize frame buffer to given resolution */
void SampleRenderer::resize(const vec2i &newSize)
{
// if window minimized
if (newSize.x == 0 | newSize.y == 0) return;
// resize our cuda frame buffer
colorBuffer.resize(newSize.x*newSize.y*sizeof(uint32_t));
// update the launch parameters that we'll pass to the optix
// launch:
launchParams.fbSize = newSize;
launchParams.colorBuffer = (uint32_t*)colorBuffer.d_ptr;
}
/*! download the rendered color buffer */
void SampleRenderer::downloadPixels(uint32_t h_pixels[])
{
colorBuffer.download(h_pixels,
launchParams.fbSize.x*launchParams.fbSize.y);
}
这里开始渲染。先将主机(cpu)中的launchParams上传到设备的缓冲区中,这样设备就会将渲染结果写到launchParams内。注意launchParams是一个不稳定的缓冲区(因为不断地在写入),因此如果要获得某一时刻地launchParams,必须调用那段downloadPixels函数将launchParams的像素信息写入到新的内存中。
4、渲染
创建一个main.cpp:
#include "SampleRenderer.h"
#define STB_IMAGE_WRITE_IMPLEMENTATION
#include "3rdParty/stb_image_write.h"
/*! \namespace osc - Optix Siggraph Course */
namespace osc {
/*! main entry point to this example - initially optix, print hello
world, then exit */
extern "C" int main(int ac, char **av)
{
try {
SampleRenderer sample;
const vec2i fbSize(vec2i(1200,1024));
sample.resize(fbSize);
sample.render();
std::vector<uint32_t> pixels(fbSize.x*fbSize.y);
sample.downloadPixels(pixels.data());
const std::string fileName = "osc_example2.png";
stbi_write_png(fileName.c_str(),fbSize.x,fbSize.y,4,
pixels.data(),fbSize.x*sizeof(uint32_t));
std::cout << GDT_TERMINAL_GREEN
<< std::endl
<< "Image rendered, and saved to " << fileName << " ... done." << std::endl
<< GDT_TERMINAL_DEFAULT
<< std::endl;
} catch (std::runtime_error& e) {
std::cout << GDT_TERMINAL_RED << "FATAL ERROR: " << e.what()
<< GDT_TERMINAL_DEFAULT << std::endl;
exit(1);
}
return 0;
}
}
这部分就很明确了。定义下画布大小,实例化一下SampleRenderer,调用render函数并download像素结果即可。由于我们没有用opengl的glwindow库来创建视窗,只能靠stbi_write_png写出结果:

艰辛……这就是图形api,画个最简单的三角形都如此坎坷。下一节我们开始逐步引入视窗、三角形求交、模型渲染、纹理贴图、阴影绘制等内容。
You may also Like

Optix光线追踪渲染器(五)直接光采样数学推演与实现

Optix光线追踪渲染器(四)路径追踪算法与材质实例

3 Comments
Scofield
16th 12 月 2023 - 上午1:00大佬,我使用那段python代码进行转换,出现RuntimeWarning: line buffering (buffering=1) isn’t supported in binary mode, the default buffer size will be used这是为什么呢?求解答!
pladmin
18th 12 月 2023 - 上午2:31感觉这个是python的包或者底层的bug,俺没遇到过,可以去stackoverflow网站看看…我觉得重装下python会好一些。
dingdang
11th 1 月 2024 - 上午11:29可以直接用cuda内的工具bin2c 转.c
bin2c -c –padd 0 –type char –name embedded_ptx_code E:\program\devicePrograms.cu.ptx > E:\program\devicePrograms.c