


【论文复现】基于MUNIT对抗模型的多模态风格迁移技术
- 13 12 月, 2021
- by
- pladmin
博客摘要
本篇blog我们将复现一篇关于多模态风格迁移技术的论文“Multimodal UnsupervisedImage-to-Image Translation”。风格迁移指的是输入一张图片,在保证图片主体内容不变的前提下,给图片换一种风格模式。本篇paper作者使用自研的MUNIT模型实现了多模态风格迁移技术,主要步骤如下:1、将数据集的图像降维成两类低维code:内容code和风格code,这里涉及到了Auto-encoder等降维思想;2、将内容code与另一个图像域的风格code结合,产生风格迁移,对新结合的code作decoder生成结果图像;3、将风格code重建,使得同一个风格域中存在多种不同风格code,提升生成图像的多样性;4、使用GAN中的鉴别器将结果图像与目标域的图片进行对比和误差反传,这里涉及到了GAN模型的知识。
接下来我会先介绍几种经典降维算法PCA和auto-encoder,再介绍用于图像生成鉴别对抗的GAN网络,最后根据上述知识来复现论文的全部步骤。
Part1 降维思想
在说encoder之前,先复习一下无监督学习的相关知识。无监督学习是一种不需要提前对数据集打标签的机器学习方法,它主要有两类功能:聚类和降维,事实证明纯纯的聚类算法有些以偏概全,因此很多时候我们会采取降维的算法来全面对数据进行描述。降维算法主要有两大步骤:化繁为简和无中生有,如图所示:
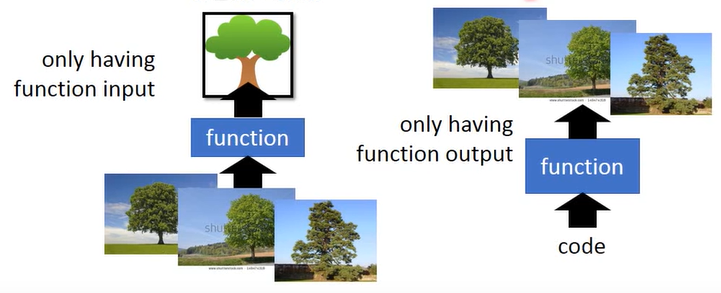
左侧将图片中同类的内容抽象成了一个简单的图像,即化繁为简;右侧将一段抽象的代码扩展成了有意义的图片,即无中生有。而本篇blog就是围绕着如何将数据集的图片简化为低维数据,再将低维数据无中生有为可视图片的操作。
接下来举一个最简单的降维算法的例子:

这里左图是一些高维(三维)数据,每个数据都带有一些有意义的属性,比如颜色。我们可以分析它们的分布特点,通过一个函数function将这些数据降低成二维,即映射到二维空间中,且保证它们能够很好地根据颜色属性分离到不同的位置上,从而完成聚类的目的。因此,降维本质上是一种简化问题的操作。换言之,降维的目的是为了探索如何用最少的维度信息将一类事物特征描述得更清晰。
Part2 PCA降维算法
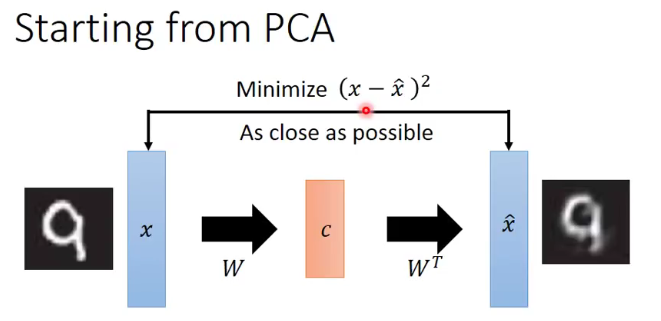
那么具体如何实现降维算法呢?这里首先提出的是PCA算法,全称是Principle component analysis,即主成分分析算法。它的思想是将高维数据乘一个降维矩阵,从而得到一个低维数据。例如输入一个100×1的向量,矩阵是一个10×100的矩阵,那么乘完以后得到的就是一个10×1的向量了。假设高维数据是x,降维矩阵是w,输出的降维结果是一维的z,那么我们可以这样降维:

相当于将x向量投影到了一个轴上,最后取其投影长度作为降维后的结果。那么,问题的关键就是:如何选择投影的轴,即如何选择降维矩阵w?举个游戏的例子,假设我们有攻击力和防御力两类特征,现在需要把它投影为一个特征,我们可以将其投影到橙色的轴上:

为什么我们选择了橙色线条作为投影的轴呢?因为我们要保证:降维以后尽量保留更多的信息,即保证更大的区分度。当我们把这些点投影到橙色的线条轴上时,这些点可以获得最大的方差,也就造成了更大的区分度,这是我们想要的效果。因此,降维本质上就转化为:如何设置降维矩阵w,使得数据投影到对应的轴上后方差最大。用数学符号来描述,就是这样:
$$||W||_2=1$$
$$z=Wx$$
$$\frac{1}{N}\sum(z_k-\bar{z})—>max$$
上面是降到一维的情况,如果要降到二维(z1,z2)就是这样:
$$||W_1||_2=1, ||W_2||_2=1 $$
$$W_1·W_2=0$$
$$z_1=W_1x, z_2=W_2x$$
更高维度的以此类推。这里的数学推导比较冗长,也不是本篇blog的重点,只要知道我们的目的是找到一系列降维矩阵W_k使得所有数据降到指定维度后方差最大即可。
前面我们讲的都是化繁为简,现在我们把眼光放到“无中生有”这步上,也就是把前面得到的降维后的低维数据,通过一个逆变换W^T,变换回高维数据上,这样我们就完成了由低维数据生成高维数据的操作了。这里要注意的是:降维后数据的方差越大,数据特征越明显,这样在做无中生有的升维操作时还原效果也就越好。因此,找到合适的W使得降维数据方差最大是非常重要的,不仅决定了化繁为简的质量,还决定了无中生有的质量。
因此,PCA的完整流程可以由下图表示:
Part3 auto-encoder思想
auto-encoder的本质和PCA算法比较像,干的也是同一件事情:
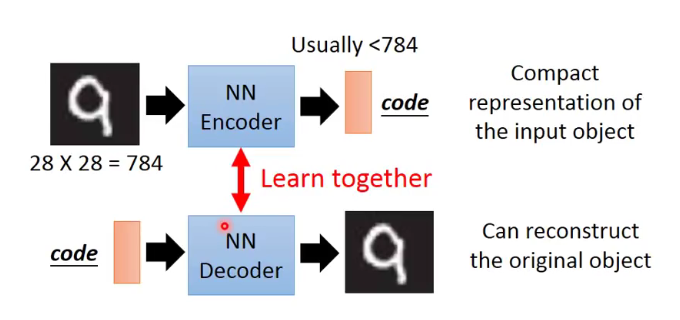
唯一的区别就是,PCA的数学逻辑非常严谨,且它只能解决线性系统的问题。对于非线性系统,我们就需要用auto-encoder自编码器来完成W转换矩阵的任务(我们要复现的论文就采取的这种思路)。auto-encoder就是采用了背靠背的全连接层,使用了类似神经网络的思想来拟合一个玄学的W:
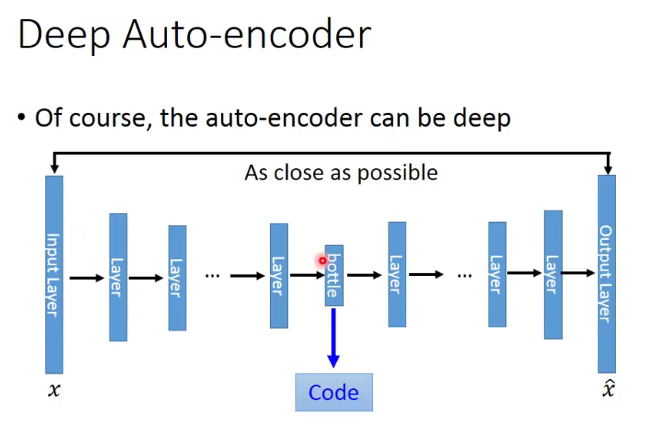
对于这样的网络,假设降维的第一步为W1,其对应的是升维的最后一步W1^T,当我们训练W1的同时可以立刻把W1^T给训练出来,而不需要按照顺序经过W2、W3…W3^T、W2^T等等。具体流程就是:我们用一个W1将图片降维为Z,然后W1^T立刻将Z升维为结果图像,将原图和结果图作对比,从而继续调整W1和W1^T。
下面是PCA和auto-encoder的一个对比:
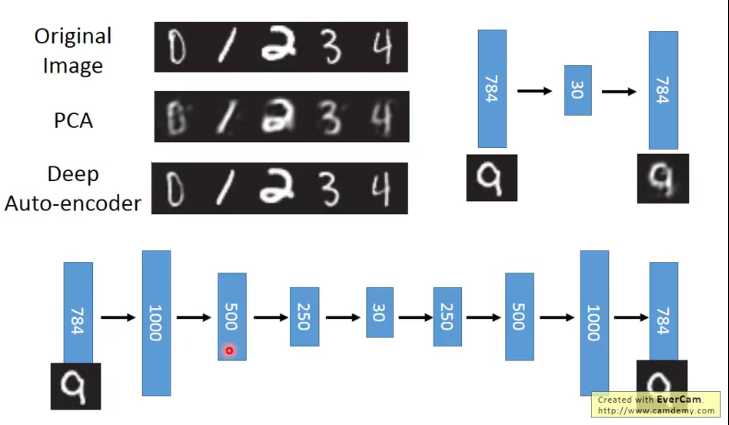
可以看到,PCA本质上就是通过数学推导拟合出一个W和W^T,而auto-coder使用炼丹术层层训练,从而得到能解决非线性系统的一堆W,使得降维和升维的效果都最好。我们要复现的这篇论文中使用的是卷积神经网络来生成code,相当于我们auto-encoder的W变换就是卷积降采样的过程,W^T变换就是逆向卷积的过程。
以上就是auto-encoder的算法核心了。当然它也有一些变种,比如denoising-auto-encoder,会在数据集上加一些噪点,送入到网络中,最后期望输出的是没有噪点的图像。这也比较好理解,就是训练了网络自动去除噪音、排除干扰的能力,从而提升网络的鲁棒性:

与其思路类似的还有contractive-auto-encoder,它的意义是稍微改变输入数据的内容,但要保证输出结果不变,和加噪声的encoder是异曲同工的。至于加了稀疏惩罚项的Parse-Auto-Encoder算法我目前还没学会,就先搁置了。
这里还想拓展一个知识点:auto-encoder网络的思想也被应用到了另一类网络上——Deep Belief Network,即深度信念网络。它主要由若干个受限玻尔兹曼机RBM层和一个反向传播BP层构成,它的主要思想是使用概率判别模型,解决收敛较慢、收敛受限局部最优的问题,当然训练基于的数学原理也比较复杂,就先略过了。我们只关心它的网络结构:
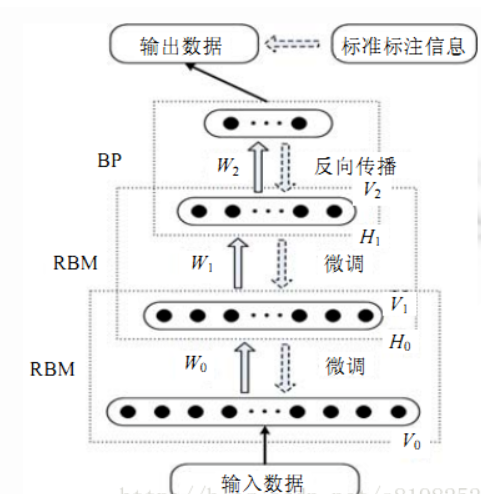
可以看到它与前面提到的自编码器网络异曲同工,都是先将数据进行逐层降维,最后得到一个低维数据,训练期间不断调整各个网络层的参数。区别在于DBN网络的调整中枢点在最后的BP网络上,即只有降维的全部流程走完以后,才能根据BP网络的结果进行逐层回调,调整网络权重参数。
接下来我们看一下每一层的训练细节。BP网络太基础了就不说了,主要看一下RBM层:
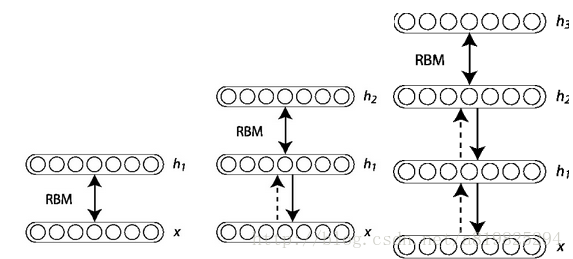
在训练时,首先把数据向量x和第一层隐藏层作为一个RBM,训练出这个RBM的参数(连接x和h1的权重,x和h1各个节点的偏置等等),然后固定这个RBM的参数,把h1视作可见向量, 把h2视作隐藏向量,训练第二个RBM, 得到其参数,然后固定这些参数,训练h2和h3构成的RBM,以此类推,就可以把各个RBM层的数据训练完毕。最后喂给BP后,再根据反向传播的loss逐层返回并调节。
Part4 GAN网络
对于风格迁移技术,我们相当于要对一个图片从某一个域的风格向另一个域的风格进行迁移。那么如何判断我们生成的图片风格是否和目标域的风格相同呢?这里我们就需要GAN网络了。
GAN包含了两套独立的神经网络,一个扮演生成器,生成类似真数据的随机样本,作为假样本;另一个扮演分类鉴别器,来分辨生成数据的真假。很显然它们互为对抗目标,如图:
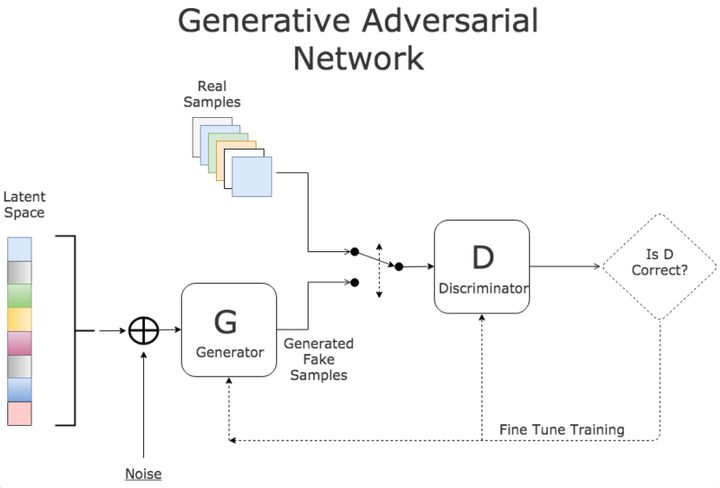
D是一个图片分类鉴别器,例如它可以区分不同的动物;生成器G的目标就是绘制出非常接近的伪造图片来欺骗D,做法是选取训练数据潜在空间中的元素进行组合,并加入随机噪音,例如在这里可以选取一个猫的图片,然后给猫加上第三只眼睛,以此作为假数据。在训练过程中,D会接收真数据和G产生的假数据,它的任务是判断图片是属于真数据的还是假数据的。对于最后输出的结果,可以同时对两方的参数进行调优。如果D判断正确,那就需要调整G的参数从而使得生成的假数据更为逼真;如果D判断错误,则需调节D的参数,避免下次类似判断出错。训练会一直持续到两者进入到一个均衡和谐的状态。
训练后的产物是一个质量较高的自动生成器和一个判断能力较强强的分类鉴别器。前者可以用于自动化创作,而后者则可以用来进行自动化分类。
有关GAN可以学习的知识还有很多,就不过多解读了。在这篇论文中我们主要就是把降维升维的auto-encoder神经网络作为GAN架构中的生成器Genertor,并外置一个优秀的分类鉴别器Discriminator,来判断做了风格迁移以后的图像,到底是不是以假乱真到了能通过分类鉴别器的考验,并将这种结果返回给降维升维的生成网络,进行参数微调。
Part5 论文解读
在了解了降维技术和判别技术后,解读论文中的风格迁移技术就比较容易了。它的技术可以概括为以下几个步骤:0、设计并预训练好一个具备encoder和decoder功能的神经网络;1、将数据集的图像降维成两类低维code:内容code和风格code;2、将内容code与另一个图像域的风格code结合,产生风格迁移;3、对新结合的code用decoder升维生成结果图像;4、将生成的图像再次分解成两个code(即重建)对于原来的code计算误差反向传播;5、使用GAN对结果图像进行判别+对抗训练。这里我们直接给出神经网络的设计架构:

接下来我们将依据这个网络架构图,逐个分析每一步所做的事情。
①降维操作
首先就是降维操作。这里我们把图像降维成了两种不同的code:内容code和风格code(原文叫content code&style code)。先说内容code,主要描述的是图像中的语义,例如输入进去的是一个圆形加一个方形的图像,那么内容code就要保留这些图像的语义特征;再说风格code,它其实描述的就是对象的性质,例如是猫还是狗,是冬天还是夏天,是高跟鞋还是运动鞋。也就是说内容code记录的是图像的大体形状和线条构成,而风格code记录的是一些对象实体的鲜明特征。
根据上面的网络架构图我们可以得到这两种code的生成方式。对于内容code,我们先通过若干个卷积层对图像进行降采样,然后使用深度残差网络会用到的残差块(Residual Blocks),最后生成低维的内容code;对于风格code,我们先通过若干个卷积层对图像进行降采样,然后经过一个全局池化层和一个全连接层,最后生成低维的风格code。这样,我们就通过神经网络得到了这两类code。
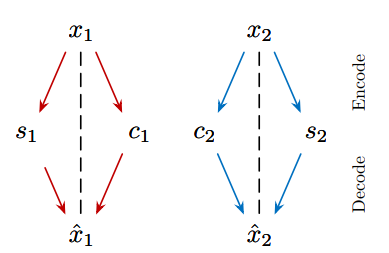
如下图,假设我们有两张图片x1和x2,它们隶属于不同的风格域X1和X2。进行降维后,我们分别得到了不同的内容code:c1和c2,以及不同的风格code:s1和s2。内容code我们可以直接进行共享,而风格code不进行共享。
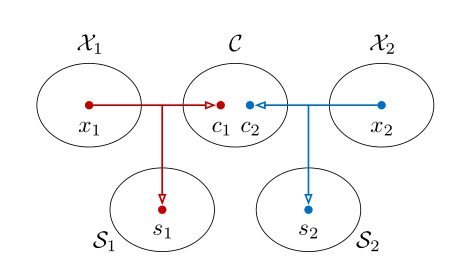
②code交叉结合
前面我们提到了,我们有两张不同风格的图片x1和x2,假如我想保留x1的画面主题内容,但是将风格转换成x2图片中的风格,很显然我们只需要将x1的内容code:c1,以及x2的风格code:s2结合在一起就好了。这里其实用到了我们前面提到的denoising思想,即适当加入一些噪声后进行交叉,目的是提升网络的鲁棒性。
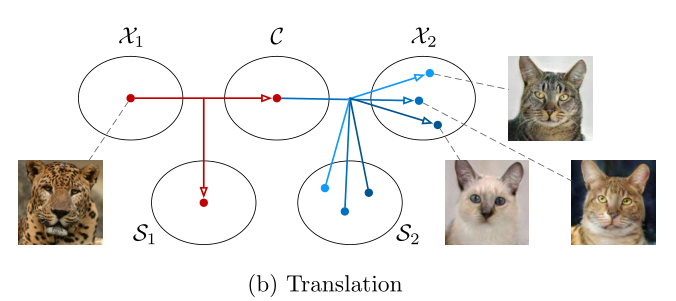
如上图所示,x1的风格code:s1其实没有什么用了,重点是保留c1,与不同的风格code结合,就能形成不同的风格图形x。
这里我们要提一嘴的是,这篇论文的创新点就在于其解耦性:将内容和风格完全分开,这样我们只要重建一下风格code,就能保证其仍在风格域中,但又微调了风格特征,这样结合同一个内容code也能生成多个风格大体相同但细节上又很不相同的图片。(如上图,S2风格域中有很多个重建过得风格code,与同一个内容code结合后生成了同域不同风格的图片x)而对于有些传统的生成模型,风格不会被重建,一个域只包含一个风格code,因此给定一个内容code,同一个域只能生成全部一样的图片,缺乏灵活性。
③升维操作Decoder
上一步我们只是说了交叉结合的抽象形式。具体的交叉方法以及升维的过程,仍然要参考网络架构图:对于风格style,先由多层感知器(MLP)动态生成参数,再经过自适应实例规范化层(AdaIN)。经过这些处理后,我们将内容code部分和风格code部分在残差块中进行糅合,然后进行上采样(相当于前面降采样的逆过程)得到图片。
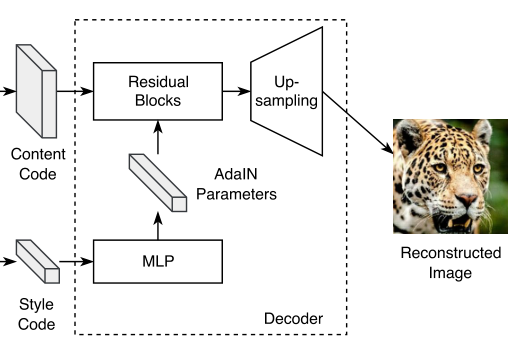
原论文中还强调了下自适应实例规范化层使用的公式,这一部分我没学过所以就只能摆下公式了。

④code重建
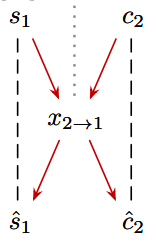
code重建实际上是这样操作的:前面我们成功将c1和s2结合在一起,经过decoder生成了图像。这时我们可以将生成的图像再次放进网络,生成新的c’和s’。计算原先的c、s和再生成的c’和s’之间的差距loss,如果差距较大,那么可以将这个loss反向传播,重新调整网络参数。如下图:
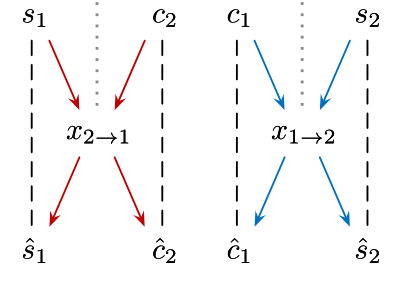
虚线两端就是我们需要对比计算loss值的两个量。
⑤GAN对抗训练
得到了风格迁移后的图片就完了吗?还没有,因为我们还没有评估这个风格迁移的效果如何。这个时候就需要请出我们的对抗生成模型GAN了,我们前面给出的网络就是生成器,而生成的图片就是假数据;我们还需要另外设置一个分类鉴别器,来对这些假数据进行真伪的判别。
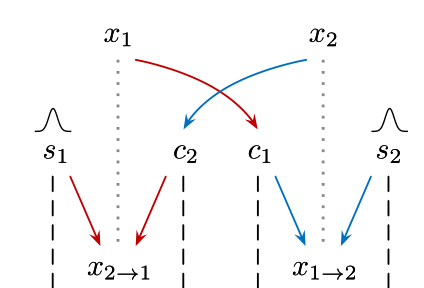
仍然使用这张图,GAN的鉴别器比较的就是x1以及从X2域中风格迁移过来的x2→1(隔点线两端的内容)。如果鉴别器轻松识破,那么就证明风格迁移效果不好,这样就将GAN的loss误差反传给生成器的网络中,进行微调,然后企图生成更精准、更合适的风格code,结合内容code后形成图片来欺骗鉴别器。鉴别器如果鉴别失败了也会对自己的网络进行调节,从而变得更强,这样鉴别器和生成器道高一尺魔高一丈,互相促进,最后我们就能得到两个很强大的网络了:一个是风格无损迁移的生成器,一个是火眼金睛的风格迁移效果检验器。
其实到这里,该论文描述的风格迁移过程就差不多结束了。这篇paper花了一定篇幅在推导数学计算:主要围绕着网络层的设计以及loss的计算公式。整理这些数学推导当然非常有意义,但是写在博客里显得冗长又杂乱,因此只放了个实现的流程和原理。
⑥不同网络结果对比
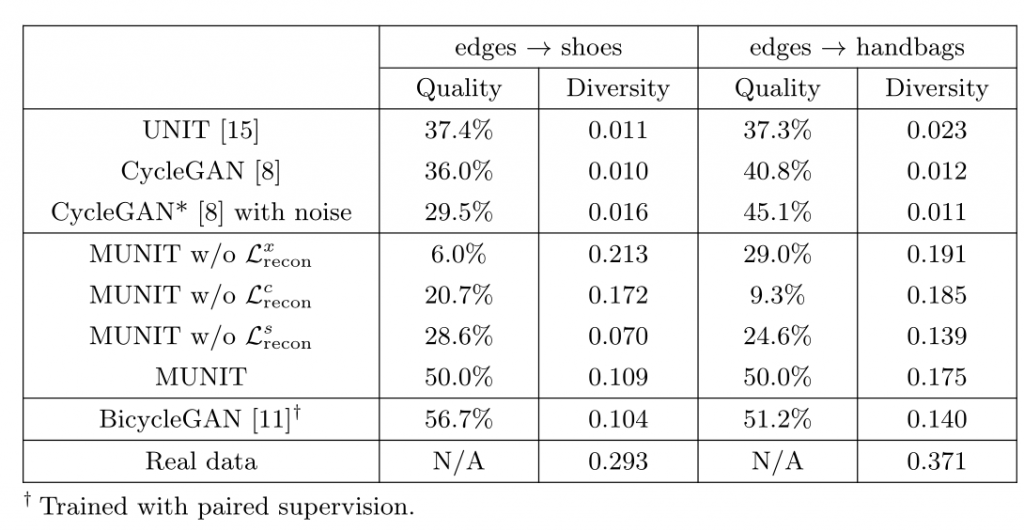
论文中提到了很多种GAN的模型,如Unit,CycleGAN,CycleGAN*,BicycleGAN等,分别与自己的MUNIT模型作了对比:作者使用这几个网络分别跑了鞋子、包、动物、街景、季节的数据集,最后得到了下图的效果:

可以看到,MUNIT在多样性上彻底击败了UNIT、CycleGAN和CycleGAN*,和Bicycle-GAN旗鼓相当(生成质量略逊一筹,生成多样性略胜一筹)。下面的表格用数据说明了这一点:
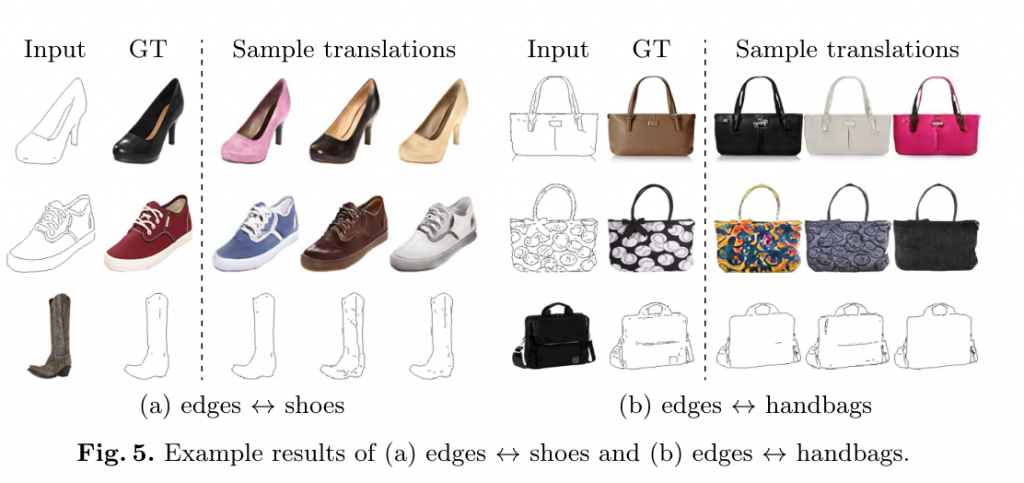
⑦生成结果一览



Part6 论文复现
①源码文件
在了解了算法的大体流程后,我们去网站:https://github.com/nvlabs/MUNIT下载源码。源码包涵以下文件:
configs文件夹下面包含的是.yaml后缀的配置文件,其中记录了神经网络的一些配置和训练参数;
datasets文件夹下面包含的是一系列训练用的数据集,其中需要用txt文档将数据集的各个图片名称保存下来;
docs文件夹下面就放了个原理图,没啥用;
inputs文件夹下面包含的是需要进行风格迁移的输入图片;
models文件夹下面包含的是.pt后缀的权重文件,当我们训练完神经网络以后其权重结果将保存在这个文件中;
outputs文件夹是我自己创建的(必须要建),下面包含的是风格迁移后的输出结果图片;
results文件夹下面包含的是作者得到的一些预测结果,做了一些展示,没啥用;
scripts文件夹下面是在服务器上进行训练的批处理指令;
data.py是用来处理数据集图片的程序;
Dockerfile是用来快速配置环境和包的指令集合;
networks.py是神经网络的主要架构;
test.py和test_batch.py是用来进行风格迁移操作的,即输入一张或一套图片,输出迁移后的结果;
trainer.py编写了对神经网络的各种训练操作,train.py可以调用trainer中的操作来完成全部训练流程;
utils.py存储了一些工具和轮子,例如加载数据集、权重初始化等等。
②网络架构
MUNIT的神经网络结构主要在networks.py这个文件中,这里记录了生成器和判别器的主体结构。为了便于分析,我们把网络架构图再粘上来:
上图展示的主要是GAN架构的生成器部分。生成器的主体框架是这部分:
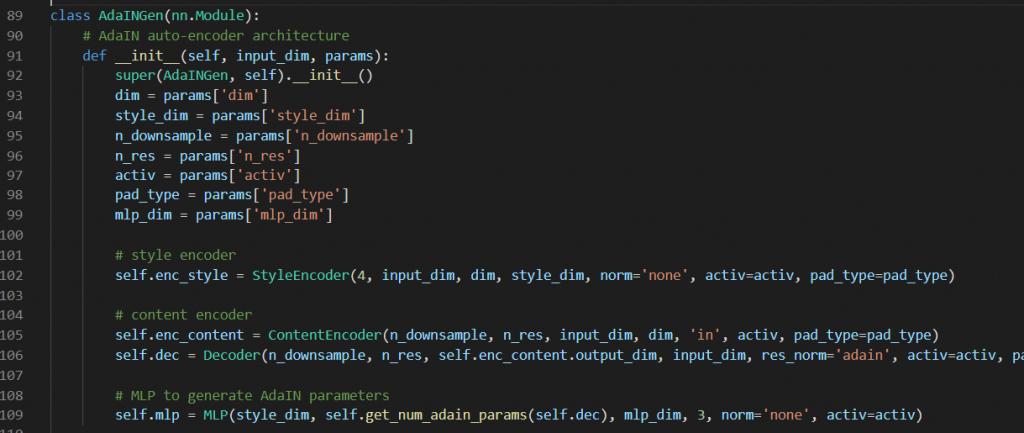
我们知道生成器主要由encoder和decoder构成,其中encoder又分为content encoder和style encoder两部分,其对应的内容如下:


从上图可以看到,content encoder就是由n_downsample层 用来降采样的卷积块构成,之后追加了一个深度残差网络的residual残差块,最后输出的content code的shape为(4,256,64,64)。
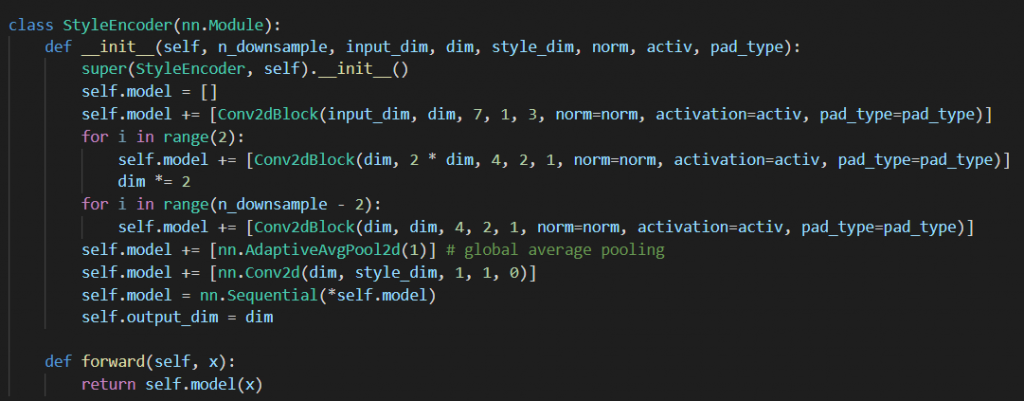
从上图可以看到,style encoder就是由n_downsample层降采样卷积块、自适应全局池化层和一个全连接层。这里可以与content encoder同步得到两类目标code。输入图像shape为(N,3,256,256),则输出的style code为(N,8,1,1)。
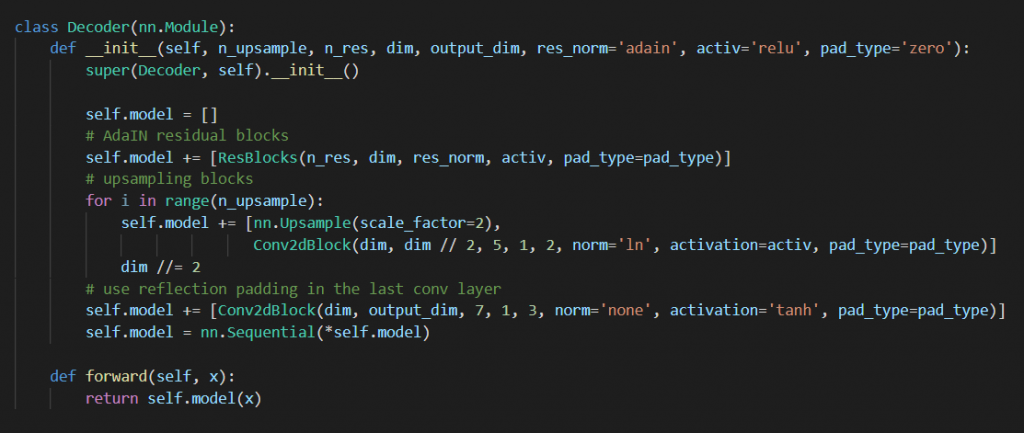
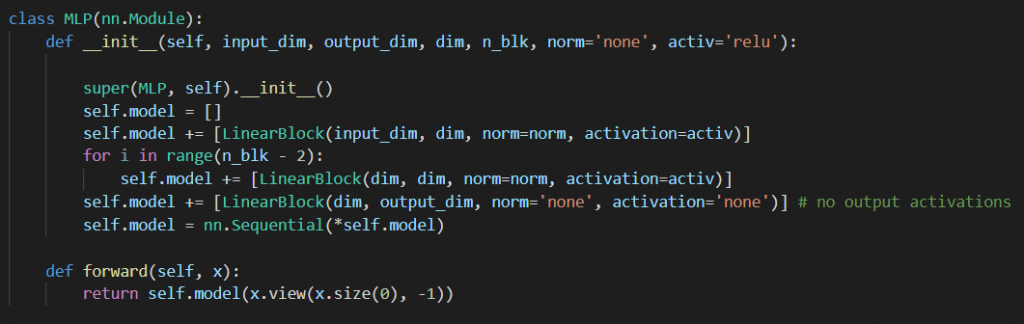
从上图可以看到,encoder对应的decoder首先有一个MLP结构,MLP的作用是将得到的style code分解为weight和bias。接下来包含若干个resblock残差块,然后进行升采样,生成高维图片数据。
生成器的主体结构就是这些了,我们再来看一下鉴别器的结构:

鉴别器结构和我们传统的卷积神经网络作目标识别的逻辑有点像,核心思维就是卷积。这里我们的鉴别器有多个(具体数量在config中自己调),每个鉴别器含有4层卷积block与一个conv1x1,每个鉴别器输入图像大小分别为256,128,64,32…以此类推(体现multi-scale);输出分别为(N,1,16,16),(N,1,8,8),(N,1,4,4)…
如此,我们便得到了生成器和鉴别器组成的完整对抗网络了。其实关于trainer也有很多内容可以分析,但是这部分几乎全是计算loss、反向传播和参数更新,没什么深究的价值,就跳过了。
③参数列表
这里作者自动给我们划分了区域,因此我们就按照区域划分来看一下网络的参数:

这些参数主要就是训练过程中存图、显示图、存模型的一些基础配置:多久显示一次?多久存一次?一次多少张?一般来说不用动这些参数。
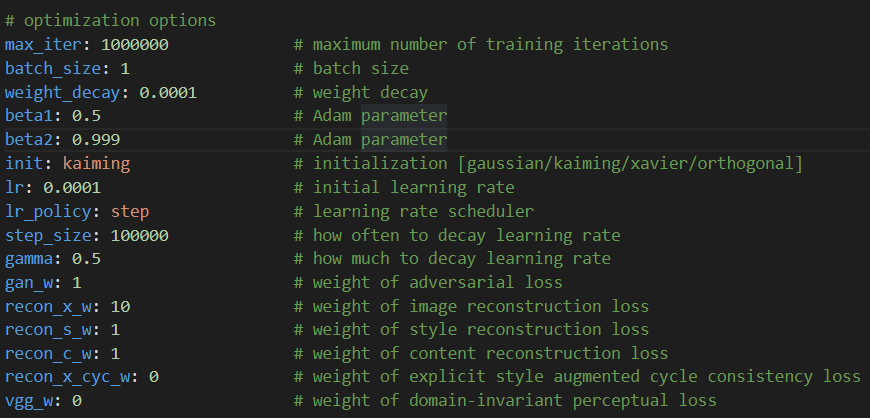
这些参数是训练相关的配置参数,基本上任何神经网络都会涉及到,例如一次训练的样本数batch_size,迭代次数iter,权重衰减weight_decay等等,这些都是非常基础的参数了,就没什么必要在这里详细解释了。
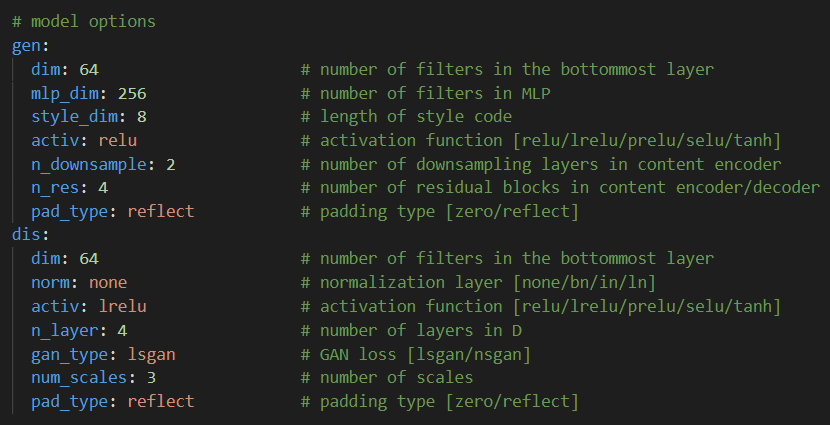
这里配置的就是两个神经网络的结构信息,对于生成器需要指定卷积底层维度,MLP维度,以及生成的style code维度等等,对于鉴别器需要指定卷积底层维度,层数,以及不同尺寸鉴别器的数量num_scales等等。
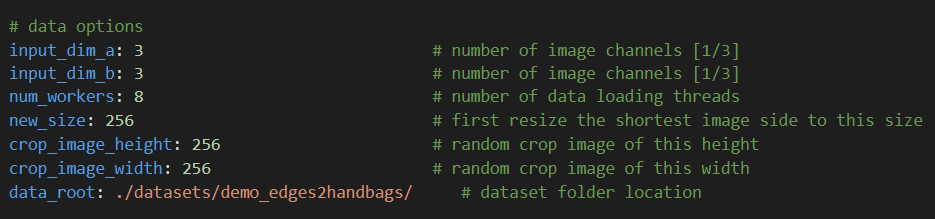
最后这部分就是配置数据集信息了,需要根据数据集图片的维度、线程数、图片扩展裁剪的尺寸以及数据集目录。
④训练过程
现在我们可以开始训练了。为了方便,我们直接使用作者内置的“鞋子轮廓 转 鞋子图案”的训练集进行训练,一共分为四个文件夹:
首先我们来看trainA和trainB。trainA包含的是一些鞋子轮廓,trainB包含的是一些鞋子图案:

trainA放的就是:能够突出图像在风格转换前的content的数据;trainB放的就是:能够突出风格style的数据。这两组数据就是用来训练生成器,也就是我们的encoder和decoder部分的。这部分的训练主要有两个方面:
第一,我们无差别的把A和B的train数据x喂进生成器,生成content code和style code后,原封不动地用decoder还原成x’,计算x和x’间的loss并调整网络,也就是如下图:
第二,我们把train A数据x降维得到的c(content)和train B数据生成的s(style)结合,然后用decoder升维成x”,再将x”降维成c’和s’,计算c和c’以及s和s’间的loss并调整网络,也就是如下图:
生成器自身的调节就结束了。接下来我们来到GAN部分,即生成器和鉴别器的互相调节部分,这里就要用到我们的test A和test B数据集了。test A存放的是假数据在进入生成器之前的图片,test B存放的是真数据:


现在开始GAN的对抗训练,我们直接把test A的数据x_a喂进生成器,然后就会生成一个假数据x_a’,此时我们把test B的真数据x_b和前面的x_a’一起送入鉴别器进行鉴别。如果鉴别器认为x_a’很真,x_b很假,那么鉴别器本身就需要继续调节;如果鉴别器认为x_a’很假,x_b很真,此时鉴别器能力要更胜一筹,这时候生成器就需要根据这个结果继续调整网络,来生成更接近真实数据的假数据。也就是如下图:
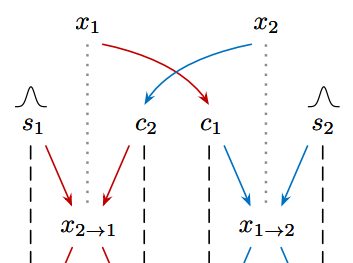
如上图,x1是假数据来源,x2是真实图。x1经过生成器后,其c1和真实图的s2结合后生成了假数据x1->2,此时把x2和x1->2一起送到鉴别器对比,就能计算出GAN的loss并调整两个网络的权重了。
训练直接运行scripts文件夹下的批处理文件就行了,代码过程就不解析了。
⑤程序运行结果
这里我们使用现成的鞋子模型和配置来实现轮廓到彩色图片的生成。我们使用指令:python test.py –config configs/edges2shoes_folder.yaml –input inputs/edges2shoes_edge.jpg –output_folder outputs –checkpoint models/edges2shoes.pt –a2b 1 –style inputs/edges2shoes_shoe.jpg,完成一个鞋子轮廓到成品鞋子的转换。
首先我们看看,规定风格的输出结果。如下图所示,左图是输入的轮廓,右图是给定的风格来源图片:

最后我们可以得到这样的结果:

我们同样可以不给定风格来源图片,让它自动生成多风格的生成结果:



但是一旦线稿不干净,污渍会在生成的图案中被放大:

3 Comments
admin
1st 9 月 2022 - 下午11:46博主,交换友情链接吗?
admin
23rd 10 月 2022 - 下午2:07博主,换友情链接吗?
晨汐网
6th 12 月 2022 - 上午8:17博主你好,你的网站做得真好,可以跟你换个友链吗?